Java学习之旅
学学Java吧!
一、Java SE基础
这里就是Java学习的开始,从这开始我的Java复习,以及笔记整理之路。
计算机预科
这都是最基础的,大概就提一下。
1、打开CMD
2、管理员身份运行CMD
3、常见的Dos命令
1 | cd 切换路径 |
Java基础
1、Java简介
Java的特性和优势
- 简单性
- 面向对象
- 可移植性
- 高性能
- 分布式
- 动态性
- 多线程
- 安全性
- 健壮性
Java的三大版本
- JavaSE: 标准版(桌面程序、控制台开发……)
- JavaME:嵌入式开发(手机、加点…..)
- JavaEE:企业级开发(Web端、服务器开发……)
Java的安装与卸载开发环境(这个网上都有的,搜下很多)
2、Hello World
- 代码
1 | public class Hello{ |
可以直接通过java先编译为字节码class文件再执行
1 | javac Hello.java --->得到Hello.class |
注释
java中的注释有三种
- 单行注释:只能注释一行文字 Ctrl + /
- 多行注释:可以注释一段文字 Ctrl + Shift + /
- 文档注释:一般用于表名文档创建者、创建日期、说明等
1 | // 单行注释 |
3、标识符和关键字
标识符
- 所有的标识符都应该以字母,$符号或者下划线开始
- 不能使用关键字作为变量名或者方法名
- 不建议使用中文或者拼音
关键字
abstract boolean break byte case catch char const class continue default do double else extends final finally float for goto if implements import instanceof int interface long native new package private protected public return short static strictfp super switch this throw throws transient try void volatile while synchronized
4、数据类型
静态类型语言
- 变量定义时有类型声明的语言
强类型语言
- 强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。
数据类型基本分类
- 基本类型
- 数值类型
- 整数
- byte 1字节 -128~127 (一字节八位)
- short 2字节 -2^15~2^15-1
- int 4字节 -2^31~2^31-1
- long 8字节 -2^63~2^63-1
- 浮点数
- float 4字节
- double 8字节
- 字符
- char 2字节
- 布尔
- boolean 1位 只有true和false两值
- 整数
- 数值类型
- 引用类型
- 类
- 接口
- 数组
- 基本类型
什么是字节
- 位(bit) 计算机内部数据存储的最小单位, 1011 1101是一个八位的二进制数
- 字节(byte) 是计算机中数据处理的基本单位,习惯用大写B表示,1B(byte字节) = 8bit(位)
- 字符:是指计算机中使用的字母、数字、字和符号。
- 1bit表示1位
- 1Byte表示一个字节1B=8b
- 1024B=1KB
- 1024KB=1M
- 1024M=1G
数据类型拓展
1 | //不同进制的表示 |
5、类型转换
由于Java是强类型语言,所以在进行某些运算的时候,需要进行对应的类型转换
1
2低 ------------------------------------------------> 高
byte -> short -> char -> int -> long -> float -> double运算中,不同类型的数据先转化为统一类型在进行运算
1
2
3
4
5
6
7
8//强制类型转换
(int)12.3 ---> 12
(double)12 ----> 12.00
// 不过要注意数据类型的大小,防止内存溢出的出现
// JDK7新特性,数字之间可以用下划线分割
int money = 10_0000_0000;
6、变量与常量
- 变量:可以变化的量
- Java是一种强类型语言,每个变量都要申明其数据类型
- Java变量是程序中最基本的存储单元,其要素包括变量名、变量类型和作用域
- 每个变量都必须要有对应的类型,可以使基本类型也可以是引用类型
- 变量名必须是合法的标识符
- 变量声明需要以分号结尾
1 | // 类变量 static |
- 变量的一些命名规范(使你的代码更加规范化)
- 所有变量、方法、类名:见名如意(可以采用英文命名)
- 类成员变量:首字母小写和驼峰原则:monthSalary
- 局部变量:首字母小写和驼峰原则
- 常量:大写字母加下划线:MAX_VALUE
- 类名:首字母大写加驼峰原则:Man,GoodMan
- 方法名:首字母小写和驼峰原则:runRun()
7、基本运算符
Java支持如下运算符
算术运算符:+,-,*,/,%,++,–
赋值运算符: =
关系运算符:>,≤,>=,<=,==,!=, instanceof
1
instanceof是Java中的二元运算符,左边是对象,右边是类;当对象是右边类或子类所创建对象时,返回true;否则,返回false。
逻辑运算符:&&,‖,!
位运算符:&,|,~,^,>>,<<,>>>
1
2
3
4
5
6
7&:按位与
|:按位或
~:按位非
^:按位异或
<<:左位移运算符
>>:右位移运算符
<<<:无符号左移运算符条件运算符: ?:
扩展赋值运算符:+=,-=,*=,/=
8、自增自减运算符、初始Math类
1 | a++ 与 ++a的区别 |
Math类的一些常见用法
1
2
3
4
5
6Math.abs(a):取a的绝对值
Math.sqrt(a):取a的平方根
Math.cbrt(a):取a的立方根
Math.max(a,b):取a、b之间的最大值
Math.min(a,b):取a、b之间的最小值
Math.pow(a,b):取a的b平方
9、逻辑运算符、位运算符
1 | && // 逻辑与:两个变量都为真,结果才为true |
1 | /* |
10、三元运算符
1 | // 三元运算符 |
11、包机制
为了更好的组织类,Java提供了包机制,用于区别类名的命名空间
包语句的语法格式是
1
package pkg1[.pkg2[.pkg3……]];
一般利用公司域名倒置作为包名;www.baidu.com —> com/baidu/www
为了能够使用某个包的成员,我们需要再Java程序中明确导入该包,使用“import”语句可完成此功能
1
import package1[.package2……].(classname | *);
12、JavaDoc
JavaDoc是用来生成自己API文档的。
参数信息
1
2
3
4
5
6- @ author作者名
- @ version版本号
- @ since指明需要最早使用的jdk版本
- @ paran参数名
- @ return返回值情况
- @ throws异常抛出情况使用方法
1
javadoc -encoding UTF-8 -charset UTF-8 Doc.java // 注意保持编码一致
流程控制
1、用户交互Scanner
Java给我们提供了一个工具类,去实现程序与人的交互,获取用户的输入,java.util.Scanner是Java5的新特性,我们可以使用Scanner类去获取用户输入。
基本语法
1
Scanner s = new Scanner(System.in);
通过 Scanner类的next()与 nextLine()方法获取输入的字符串,在读取前我们一般需要使用 hasNext()与 hasNextLine()判断是否还有输入的数据。
1
2
3
4
5
6
7
8
9
10if(scanner.hasNext()){
String str = scanner.next();
System.out.println("输入的内容为:" + str);
}
if(scanner.hasNextLine()){
String str = scanner.nextLine();
System.out.println("输出的内容为:" + str);
}next():
- 一定要读取到有效字符才可以结束输入。
- 对输入有效字符之前遇到的空白,会自动去除
- 只有输入有效字符才将其后输入的空白作为分隔符或者结束符
- next不能获取带空格的字符串
nextLine():
- 以Enter为结束符,也就是说返回的是Enter前所有字符
- 可以获取空白
2、顺序结构
- Java的基本结构就是顺序结构,除非特别指明,负责就是按照顺序一句一句执行。
- 顺序结构是最简单的算法结构
- 语句与语句之间,框与框之间是按从上到下的顺序进行的,它是由若干个依次执行的处理步骤组成的,它是任何一个算法都离不开的一种基本算法结构 。
3、选择结构
if简单选择结构
我们很多时候去判断一个东西是否可行,可行才能够去执行,这就用到if结构
1
2
3if(布尔表达式){
// 如果布尔表达式为true才执行这个代码块中的
}
if双选择结构(也就是if else)
1
2
3
4
5if(布尔表达式){
// 如果布尔表达式为true
}else{
// 如果布尔表达式值为false
}if多选择结构
1
2
3
4
5
6
7
8
9if(布尔表达式1){
// 如果布尔表达式1为true执行代码
}else if(布尔表达式2){
// 如果布尔表达式2为true执行代码
}else if(布尔表达式3){
// 如果布尔表达式3为true执行代码
}else{
// 如果以上布尔表达式值都不为true执行代码
}嵌套的if结构
1
2
3
4
5
6if(布尔表达式1){
// 如果布尔表达式1为true执行代码
if(布尔表达式2){
// 如果布尔表达式2为true执行代码
}
}switch多选择结构
- 多选择结构还有一个实现方式就是 switch case语句。
- switch case语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支。
1
2
3
4
5
6switch(参数){
case A:
case B:
case C:
default:
}
4、循环结构
- while循环
- do……while循环
- for循环
5、break & continue
break在任何循环语句的主体部分,均可用 break控制循环的流程。 break用于强行退出循环,不执行循环中剩余的语句。( break语句也在 switch语句中使用)。
continue语句用在循环语句体中,用于终止某次循环过程,即跳过循环体中尚未执行的语句,接着进行下一次是否执行循环的判定。
关于goto标签
1
2label:
while(或其他循环语句)- goto关键字很早就在程序设计语言中出现。尽管goto仍是Java的一个保留字,但并未在语言中得到正式使用;Java没有goto。然而,在 breaki和 continue这两个关键字的身上,我们仍然能看出一些goto的影子—带标签的 break和continue。
- “标签”是指后面跟一个冒号的标识符,例如:label;
- 对Java来说唯一用到标签的地方是在循环语句之前。而在循环之前设置标签的唯一理由是:我们希望在其中嵌套另一个循环,由于 break和 continue关键字通常只中断当前循环,但若随同标签使用,它们就会中断到存在标签的地方。
- goto标签由于有一些不好的方面,一般基本不使用
方法
1、何谓方法
Java方法是语句得到集合,它们在一起执行一个功能。
- 方法是解决一类问题的步骤的有序组合
- 发包含于类或对象中
- 方法在程序中被创建,在其他地方被引用
设计方法的原则:方法的本意是功能块,就是实现某个功能的语句块的集合。我们设计方法的时候,最好保持方法的原子性,就是一个方法只完成1个功能,这样利于我们后期的扩展。并且对于方法的命名,也尽可能去对应其功能,使其更浅显易懂。
2、方法的定义及调用
Java的方法类似于其它语言的函数,是一段用来完成特定功能的代码片段,一般情况下,定义一个方法包含以下语法:
方法包含一个方法头和一个方法体。下面是一个方法的所有部分:
- 修饰符:修饰符,这是可选的,告诉编译器如何调用该方法。定义了该方法的访问类型。
- 返回值类型:方法可能会返回值。 returnValueType是方法返回值的数据类型。有些方法执行所需的操作,但没有返回值。在这种情况下, returnValueType是关键字void。
- 方法名:是方法的实际名称。方法名和参数表共同构成方法签名。
- 参数类型:参数像是一个占位符。当方法被调用时,传递值给参数。这个值被称为实参或变量。参数列表是指方法的参数类型、顺序和参数的个数。参数是可选的,方法可以不包含任何参数。
- 形式参数:在方法被调用时用于接收外界输入的数据。
- 实参:调用方法时实际传给方法的数据。
- 方法体:方法体包含具体的语句,定义该方法的功能。
1
2
3
4
5
6修饰符 返回值类型 方法名(参数类型 参数名){
...
方法体
...
return 返回值;
}调用方法:对象名.方法名(实参列表)
Java支持两种调用方法的方式,根据方法是否返回值来选择,当方法返回一个值的时候,方法调用通常被当做一个值。
如果返回值为空的话,方法调用一定是一条语句
注意!!!!!
- 方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值,这句话相当重要,这是按值调用与引用调用的根本区别,以下为分析:
- 按值调用(call by value)表示方法接受的时调用者提供的值。
函数传递值流程图
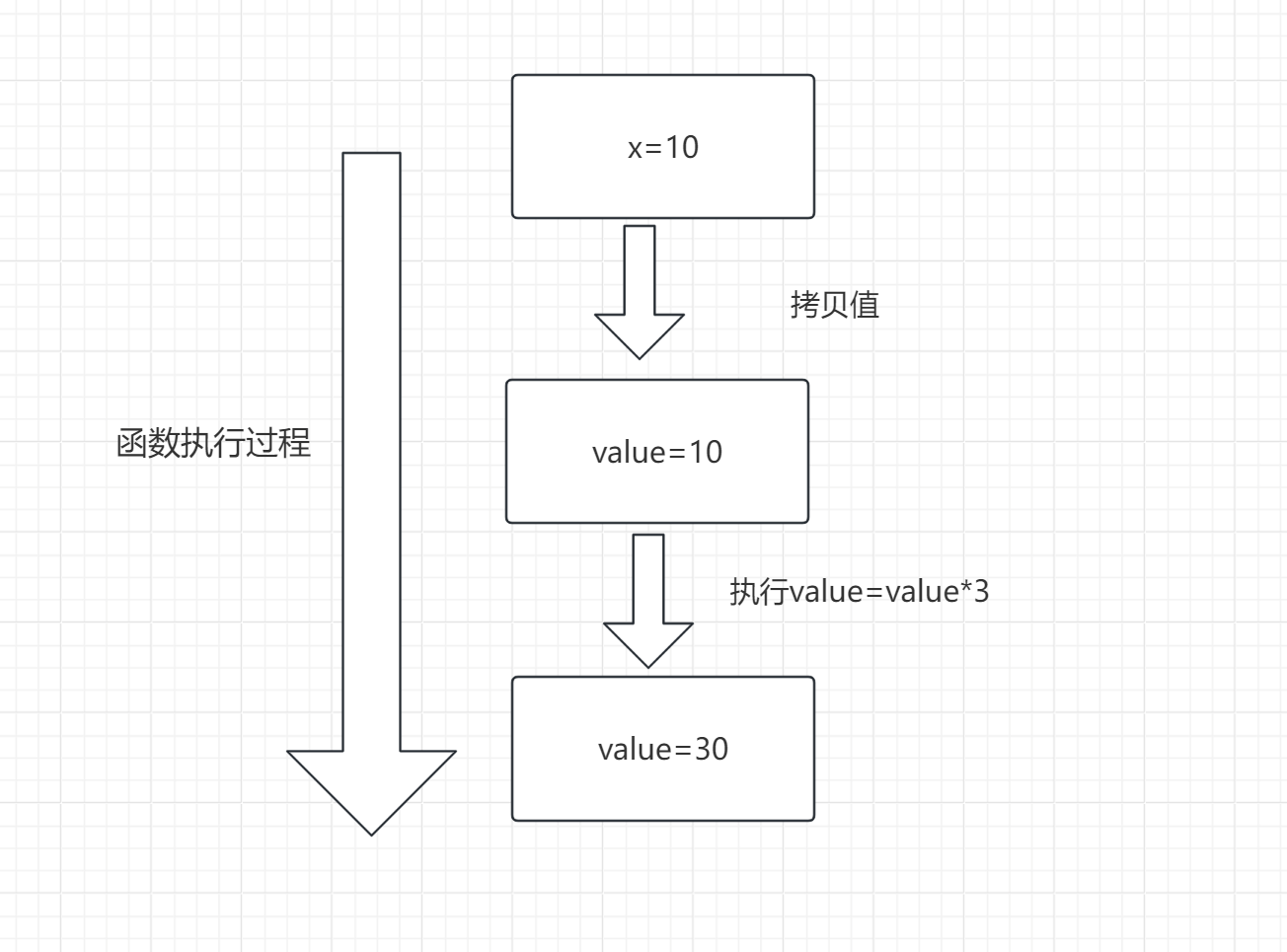
分析:
- 1)value被初始化为x值的一个拷贝(也就是10)
- 2)value被乘以3后等于30,但注意此时x的值仍为10!
- 3)这个方法结束后,参数变量value不再使用,被回收。
结论:当传递方法参数类型为基本数据类型(数字以及布尔值)时,一个方法是不可能修改一个基本数据类型的参数。
按引用调用(call by reference)
按引用调用则表示方法接收的是调用者提供的变量地址(如果是C语言的话来说就是指针啦,当然java并没有指针的概念)
当然java中除了基本数据类型还有引用数据类型,也就是对象引用,那么对于这种数据类型又是怎么样的情况呢?我们还是一样先来看一个例子:
先声明一个User对象类型:分析一下这个过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class HomeWork02 {
public static void updateUser(User student){
student.setName("subeiLY");
student.setAge(22);
}
public static void main(String[] args) {
User user = new User("SUBEI",20);
System.out.println("调用user前的值:" + user.getName() + "," + user.getAge());
updateUser(user);
System.out.println("调用user后的值:" + user.getName() + "," + user.getAge());
}
}
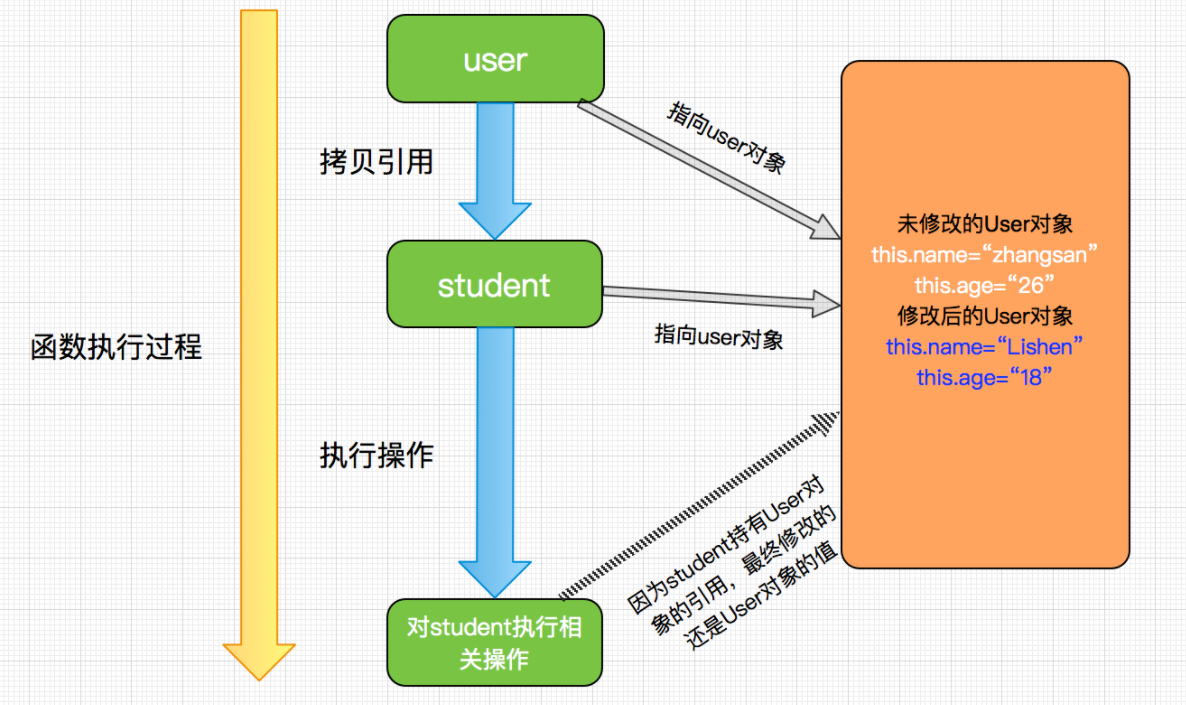
分析:
- 1)student变量被初始化为user值的拷贝,这里是一个对象的引用。
- 2)调用student变量的set方法作用在这个引用对象上,user和student同时引用的User对象内部值被修改。
- 3)方法结束后,student变量不再使用,被释放,而user还是没有变,依然指向User对象。
结论:显然,User的值被改变了,但是这是将最开始所对应得值改变了,把User的本身属性改变了,才会进行值得变化,虽然看似是按引用传递值,但是实际上是将值改变了。
- 这个过程也充分说明了java程序设计语言对对象采用的不是引用调用,实际上是对象引用进行的是值传递,当然在这里我们可以简单理解为这就是按值调用和引用调用的区别,而且必须明白即使java函数在传递引用数据类型时,也只是拷贝了引用的值罢了,之所以能修改引用数据是因为它们同时指向了一个对象,但这仍然是按值调用而不是引用调用。
- 总结
- 一个方法不能修改一个基本数据类型的参数(数值型和布尔型)。
- 一个方法可以修改一个引用所指向的对象状态,但这仍然是按值调用而非引用调用。
- 上面两种传递都进行了值拷贝的过程。
3、方法重载
- 重载就是在一个类中,有相同的函数名称,但形参不同的函数。
- 方法的重载的规则
- 方法名称必须相同。
- 参数列表必须不同(个数不同、或类型不同、参数排列顺序不同等)
方法的返回类型可以相同也可以不相同。 - 仅仅返回类型不同不足以成为方法的重载。
- 实现理论:
- 方法名称相同时,编译器会根据调用方法的参数个数、参数类型等去逐个匹配,以选择对应的方法,如果匹配失败,则编译器报错。
4、命令行传参
- 通过main函数中的args去传递参数
1 | package com.github; |
5、可变参数
- JDK1.5开始,Java支持传递同类型的可变参数给一个方法。
- 在方法声明中,在指定参数类型后加一个省略号()。
- 一个方法中只能指定一个可变参数,它必须是方法的最后一个参数。任何普通的参数必须在它之前声明。
1 | package com.github; |
6、递归
- A方法调用B方法,我们很容易理解!
- 递归就是:A方法调用A方法!就是自己调用自己。
- 利用递归可以用简单的程序来解决一些复杂的问题。它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述岀解题过程所需要的多次重复计算,大大地减少了程序的代码量。递归的能力在于用有限的语句来定义对象的无限集合。
- 递归结构包括两个部分:
- 递归头:什么时候不调用自身方法。如果没有头,将陷入死循环;
- 递归体:什么时候需要调用自身方法。
示例:使用递归求阶乘
1 | package com.github; |
数组
1、数组概述
- 数组是相同类型数据的有序集合。
- 数组描述的是相同类型的若干个数据按照一定的先后次序排列组合而成。
- 其中每一个数据称作一个数组元素每个数组元素可以通过一个下标来访问它们。
2、数组声明创建
- 首先必须声明数组变量,才能在程序中使用数组。下面是声明数组变量的语法:
1 | dataType[] arrayRefVar; // 首选的方法 |
- Java语言使用new操作符来创建数组,语法如下:
1 | dataType[] arrayRefVar = new dataType[arraySize]; |
- 数组的元素是通过索引访问的,数组索引从0开始。
- 获取数组长度:
arrays. length
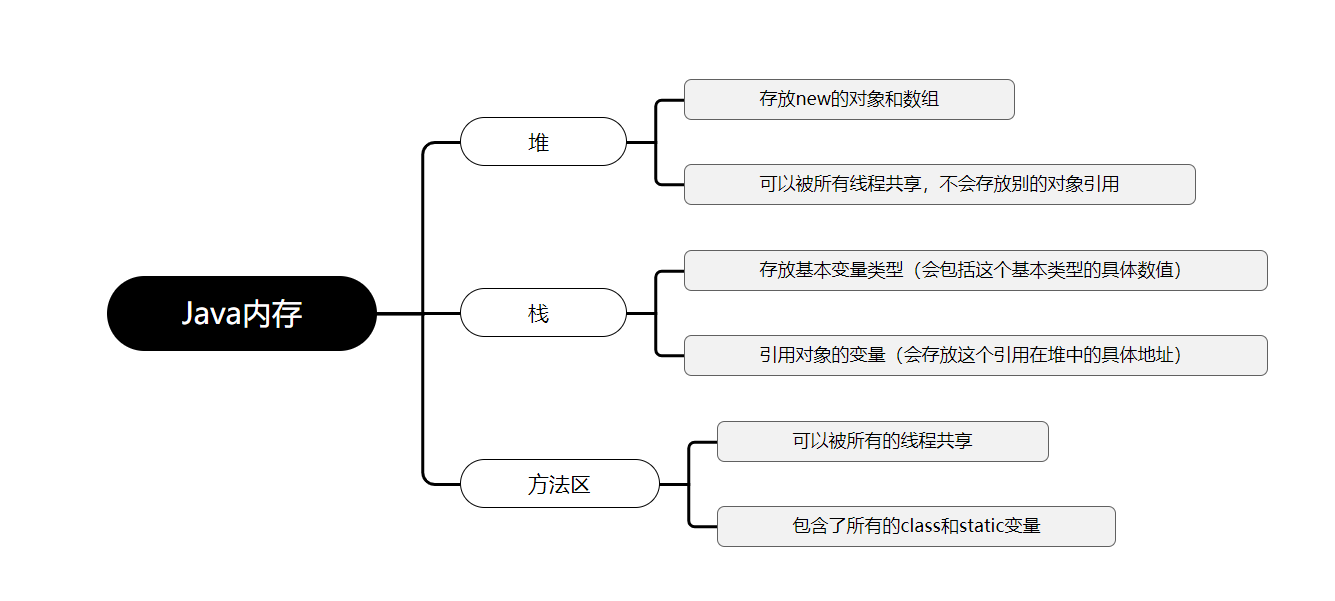
内存分析
数组的四个基本特点:
- 其长度是确定的。数组一旦被创建,它的大小就是不可以改变的;
- 其元素必须是相同类型不允许出现混合类型。
- 数组中的元素可以是任何数据类型,包括基本类型和引用类型。
- 数组变量属引用类型,数组也可以看成是对象,数组中的每个元素相当于该对象的成员变量数组本身就是对象,Java中对象是在堆中的,因此数组无论保存原始类型还是其他对象类型,==数组对象本身是在堆中的==。
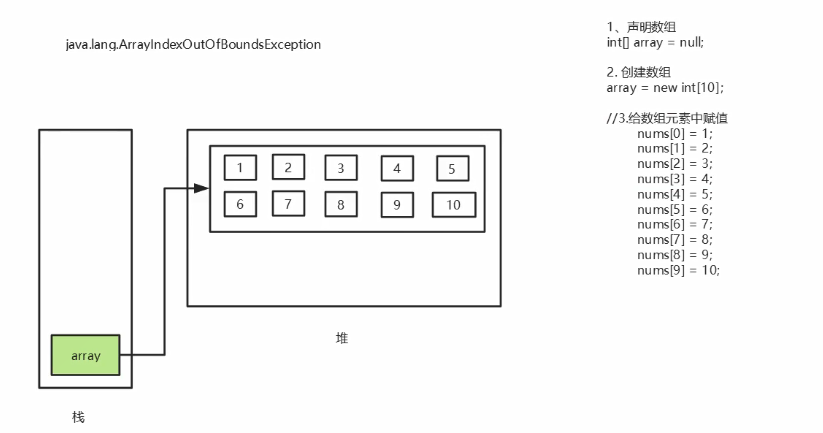
下标越界及小结:
- 下标的合法区间:[0, length-1],如果越界就会报错:
数组的下标异常:
ArraylndexOutofBounds Exception:数组下标越界异常!

数组是相同数据类型(数据类型可以为任意类型)的有序集合数组也是对象。
数组元素相当于对象的成员变量。
数组长度的确定的,不可变的。如果越界,则报:ArrayIndexOutofBounds。
3、数组使用
普通的for循环
For-Each循环
数组作方法入参
数组作返回值
4、多维数组
- 多维数组可以看成是数组的数组,比如二维数组就是一个特殊的一维数组,其每一个元素都是一个一维数组。
- 二维数组
5、Arrays类
- 数组的工具类 javautil. Arrays
- 由于数组对象本身并没有什么方法可以供我们调用但AP中提供了一个工具类 Arrays供我们使用从而可以对数据对象进行一些基本的操作。
- ==查看JDK帮助文档==。
- Arrays类中的方法都是 static 修饰的静态方法在使用的时候可以直接使用类名进行调用,而”不用”使用对象来调用(注意:是“不用”而不是“不能”)。
- 具有以下常用功能:
- 给数组赋值:通过fill方法。
- 对数组排序:通过sort方法按升序。
- 比较数组:通过 equals方法比较数组中元素值是否相等。
- 查找数组元素:通过 binarySearch方法能对排序好的数组进行二分查找法操作。
一些常用的方法
1 | 方法名 简要描述 |
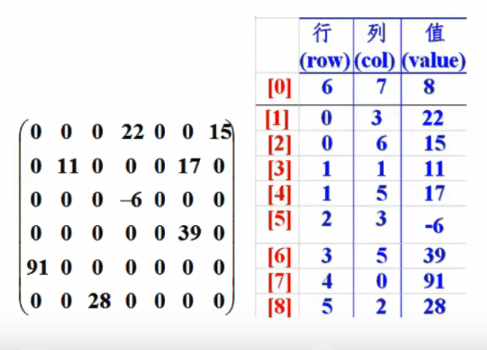
6、稀疏数组
- 当一个数组中大部分元素为0,或者为同一值的数组时,可以使用稀疏数组来保存该数组。
- 稀疏数组的处理方式是:
- 记录数组一共有几行几列,有多少个不同值。
- 把具有不同值的元素和行列及值记录在一个小规模的数组中,从而缩小程序的规模。
- 如下图:左边是原始数组,右边是稀疏数组。
面向对象(OOP)
1、初始面向对象
- 面向过程思想
- 步骤清晰简单,第一步做什么,第二步做什么…
- 面对过程适合处理一些较为简单的问题。
- 面向对象思想
- 物以类聚,分类的思维模式,思考问题首先会解决问题需要哪些分类,然后对这些分类进行单独思考。最后,才对某个分类下的细节进行面向过程的思索。
- 面向对象适合处理复杂的问题,适合处理需要多人协作的问题!
- 对于描述复杂的事物,为了从宏观上把握、从整体上合理分析,我们需要使用面向对象的思路来分析整个系统。但是,具体到微观操作,仍然需要面向过程的思路去处理。
- 面向对象编程( Object- Oriented Programming,OOP)
- 面向对象编程的本质就是:==以类的方式组织代码,以对象的组织(封装)数据==。
- 三大特征:
- 继承
- 封装
- 多态
- 从认识论角度考虑是先有对象后有类。对象,是具体的事物。类,是抽象的,是对对象的抽象。
- 从代码运行角度考虑是先有类后有对象。类是对象的模板。
2、方法的回顾和加深
方法的定义
- 修饰符
- 返回类型
- break:跳出 switch,结束循环和 return的区别。
- 方法名:注意规范就OK,见名知意
- 参数列表:(参数类型,参数名) …
- 异常抛出:疑问,参考下文!
方法的调用
- 静态方法(可以直接调用)
- 非静态方法(需要new对象才能调用)
- 形参和实参
- 值传递和引用传递
- this关键字(表示当前所在类)
3、对象的创建分析
- 类是一种抽象的数据类型它是对某一类事物整体描述/定义但是并不能代表某一个具体的事物。
- 使用new关键字创建对象。
- 使用new关键字创建的时候,除了分配内存空间之外,还会给刨建好的对象进行默认的初始化以及对类中构造器的调用。
- 类中的构造器也称为构造方法,是在进行创建对象的时候必须要调用的。并且构造器有以下俩个特点:
- 1.必须和类的名字相同;
- 2.必须没有返回类型也不能写void。
- 构造器:
- 1.和类名初问
- 2.没有返回值
- 作用:
- 1.new本质在调用构造方法;
- 2.初始化对象的值。
- 注意:定义有参构造之后,如果想使用无参构造,显示的定义一个无参构造。
4、面向对象三大特性
封装:属性私有,get/set
封装的作用:
- 提高了代码的安全性,保护数据;
- 隐藏代码的实现细则;
- 统一接口;
- 系统可维护增加了。
继承:object类、super、方法重写
- 继承的本质是对某一批类的抽象,从而实现对现实世界更好的建模。
- extands的意思是“扩展”。子类是父类的扩展。
- JAVA中类只有单继承,没有多继承!
- 继承是类和类之间的一种关系。除此之外,类和类之间的关系还有依赖、组合、聚合等。
- 继承关系的俩个类,一个为子类(派生类),一个为父类(基类)。子类继承父类使用关键字 extends来表示。
- 子类和父类之间从意义上讲应该具有”is a”的关系。
- 私有的东西无法被继承!!!
1 | super注意点: |
方法的重写
重写:需要有继承关系,子类重写父类的方法!
- 方法名必须相同;
- 参数列表列表必须相同;
- 修饰符:范围可以扩大但不能缩小: public>Protected>Default>private
- 抛出的异常:范围,可以被缩小,但不能扩大;ClassNotFoundException–> Exception(大)
- 重写,子类的方法和父类必要一致;方法体不同!
- 为什么需要重写:父类的功能,子类不一定需要,或者不一定满足!
多态
- 即同一方法可以根据发送对象的不同而采用多种不同的行为方式。
- 一个对象的实际类型是确定的,但可以指向对象的引用的类型有很多。
- 多态存在的条件:
- 有继承关系;
- 子类重写父类方法;
- 父类引用指向子类对象。
1 | - 多态注意事项: |
- 匿名代码块
- 在类创建对象时执行
- 在构造方法前执行,在静态代码块后执行
- 静态代码块
- 只会在类初次创建对象时执行
- 在构造方法、静态代码块前执行
5、抽象类和接口
抽象类
- abstract修饰符可以用来修饰方法也可以修饰类如果修饰方法那么该方法就是抽象方法如果修饰类那么该类就是抽象类。
- 抽象类中可以没有抽象方法但是有抽象方法的类一定要声明为抽象类。
- 抽象类,不能使用new关键字来创建对象它是用来让子类继承的。
- 抽象方法只有方法的声明没有方法的实现它是用来让子类实现的。
- 子类继承抽象类那么就必须要实现抽象类没有实现的抽象方法否则该子类也要声明为抽象类。
接口
- 普通类:只有具体实现;
- 抽象类:具体实现和规范(抽象方法)都有!
- 接口:只有规范!
- 接口就是规范,定义的是一组规则,体现了现实世界中“如果你是…则必须能…”的思想。如果你是天使,则必须能飞。如果你是汽车,则必须能跑。如果你好人,则必须干掉坏人;如果你是坏人,则必须欺负好人。
- 接口的本质是契约,就像我们人间的法律一样。制定好后大家都遵守。
- OO的精髓,是对对象的抽象,最能体现这一点的就是接口。为什么我们讨论设计模式都只针对具备了抽象能力的语言(比如c++、java、c#等),就是因为设计模式所硏究的,实际上就是如何合理的去抽象。
- 声明类的关键字是 class,声明接口的关键字是 interface。
1 | 抽象类和接口的区别: |
6、内部类及OOP实战
内部类就是在一个类的内部在定义一个类,比如,A类中定义一个B类,那么B类相对A类来说就称为内部类,而A类相对B类来说就是外部类了。
- 成员内部类
- 静态内部类
- 局部内部类
- 匿名内部类
异常
1、什么是异常
实际工作中,遇到的情况不可能是非常完美的。比如:你写的某个模块,用户输入不一定符合你的要求、你的程序要打开某个文件,这个文件可能不存在或者文件格式不对,你要读取数据库的数据,数据可能是空的等。我们的程序再跑着,内存或硬盘可能满了。等等。
软件程序在运行过程中,非常可能遇到刚刚提到的这些异常问题,我们叫异常,英文是:Exception,意思是例外。这些,例外情况,或者叫异常,怎么让我们写的程序做出合理的处理。而不至于程序崩溃。
异常指程序运行中出现的不期而至的各种状况如:文件找不到、网络连接失败、非法参数等。异常发生在程序运行期间它影响了正常的程序执行流程。
要理解Java异常处理是如何工作的,需要掌握以下三种类型的异常
- 检查性异常:最具代表的检查性异常时用户错误或问题引起的异常,
- 这是程序员无法预见的例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。
- 运行时异常:运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略。
- 错误ERROR:错误不是异常,而是脱离程序员控制的冋题。错误在代码中通常被忽略。例如,当栈溢出时,一个错误就发生了,它们在编译也检查不到的。
2、异常体系结构
- Java把异常当为对象来处理,并定义一个基类 java. lang.Throwable作为所有异常的超类。
- 在 Java API中已经定义了许多异常类,这些异常类分为两大类,错误Error和异常 Exception。
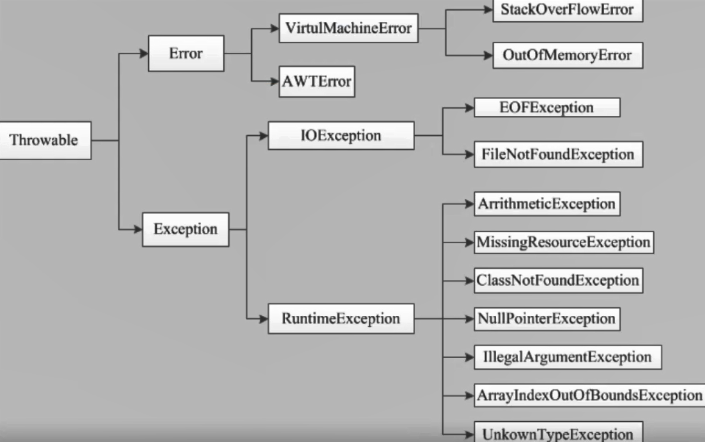
Error
- Error类对象由Java虚拟机生成并抛出,大多数错误与代码编写者所执行的操作无关。
- Java虚拟机运行错误( Virtual Machine Error),当JVM不再有继续执行操作所需的内存资源时,将出现 OutofMemory Error(OOM内存溢出)。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
- 还有发生在虛拟机试图执行应用时,如类定义错误( NoClass Deffound error)、链接错误( Linkage Error)。这些错误是不可查的,因为它们在应用程序的控制和处理能力之外,而且绝大多数是程序运行时不允许出现的状况。
Exception
- 在 Exception分支中有一个重要的子类 Runtime Exception(运行时异常)
- ArraylndexOutOfBoundsException(数组下标越界)
- NullPointerException(空指针异常)
- ArithmeticException(算术异常)
- Missing Resource Exception(丢失资源)
- ClassNotFound Exception(找不到类)等异常,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。
- 这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生;
- Error和 Exception的区别:Error通常是灾难性的致命的错误,是程序无法控制和处理的,当出现这些异常时,Java虛拟机(JVM)一般会选择终止线程;Exception通常情况下是可以被程序处理的,并且在程序中应该尽可能的去处理这些异常。
3、Java异常处理机制与处理异常
- 抛出异常
- 捕获异常
- 异常处理五个关键字:
- try、catch、 finally、throw、throws
4、自定义异常
- 使用Java内置的异常类可以描述在编程时岀现的大部分异常情况。除此之外,用户还可以自定义异常。用户自定义异常类,只需继承 Exception类即可。
- 在程序中使用自定义异常类,大体可分为以下几个步骤:
- 创建自定义异常类。
- 在方法中通过 throw关键字抛出异常对象。
- 如果在当前抛出异常的方法中处理异常,可以使用try- catch语句捕获并处理;否则在方法的声明处通过 throws关键字指明要抛岀给方法调用者的异常,继续进行下一步操作。
- 在出现异常方法的调用者中捕获并处理异常。
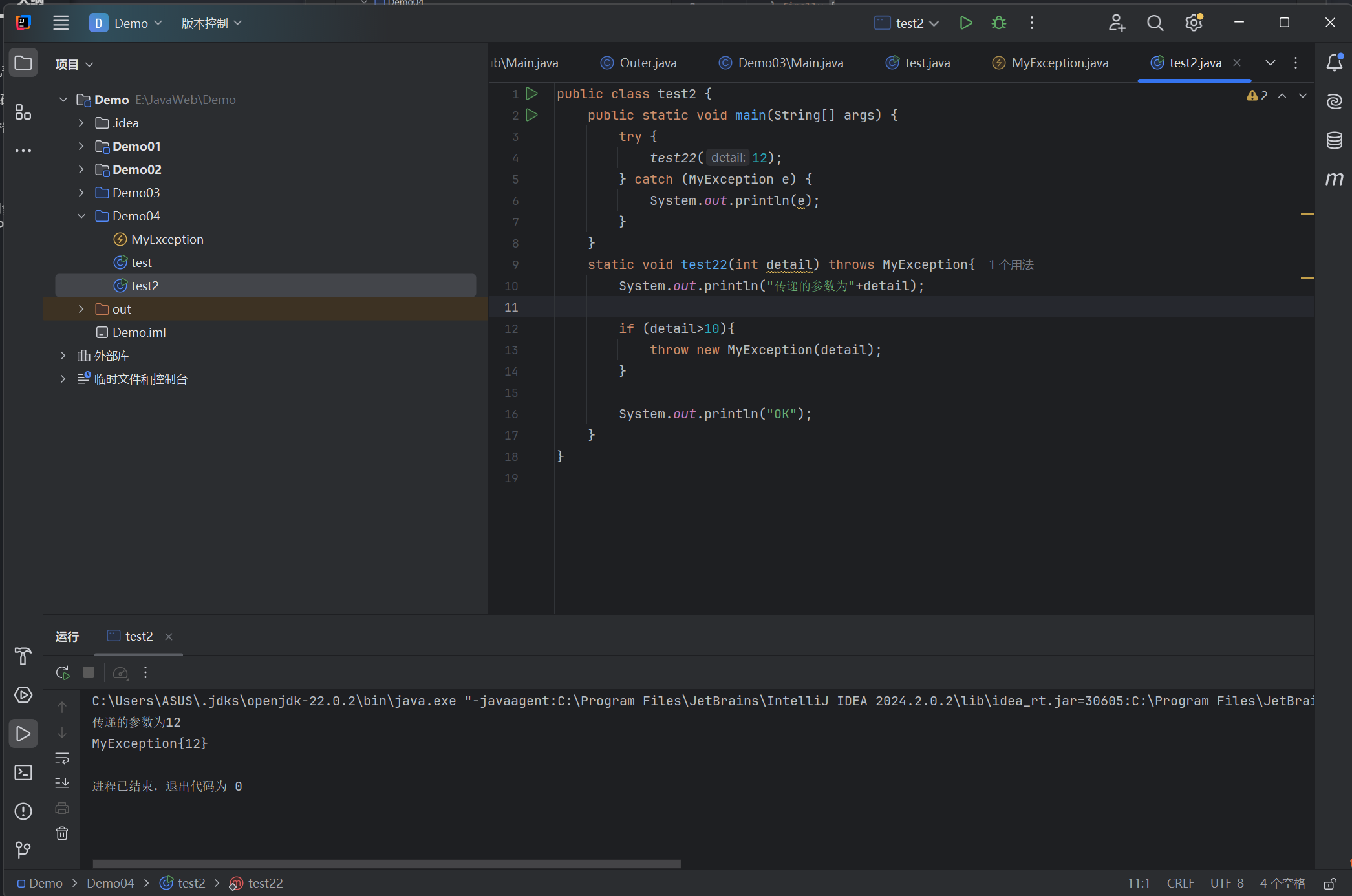
5、总结
- 处理运行时异常时,采用逻辑去合理规避同时辅助 try-catch ;
- 处理在多重 catch块后面,可以加一个 catch( Exception)来处理可能会被遗漏的异常;
- 对于不确定的代码,也可以加上try- catch,处理潜在的异常;
- 尽量去处理异常,切忌只是简单地调用 printStackTrace0去打印输出;
- 具体如何处理异常,要根据不同的业务需求和异常类型去决定;
- 尽量添加 finally!语句块去释放占用的资源。
常用类
1、字符串相关的类
1、String类的概述
1 | /** |
2、理解String类的不可见性
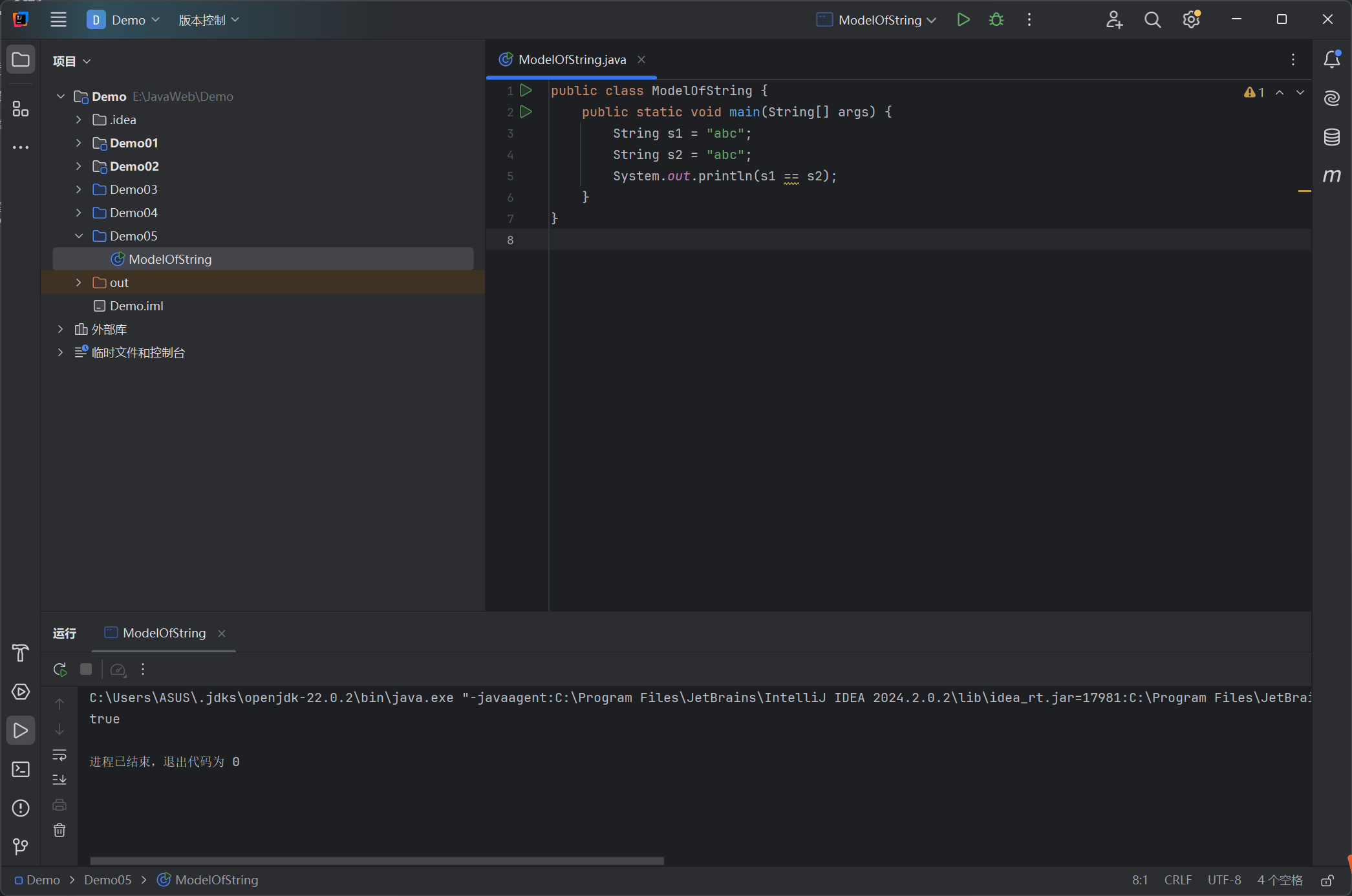
3、String不同实例化方法的对比
- String对象的创建
1 | String str = "hello"; |
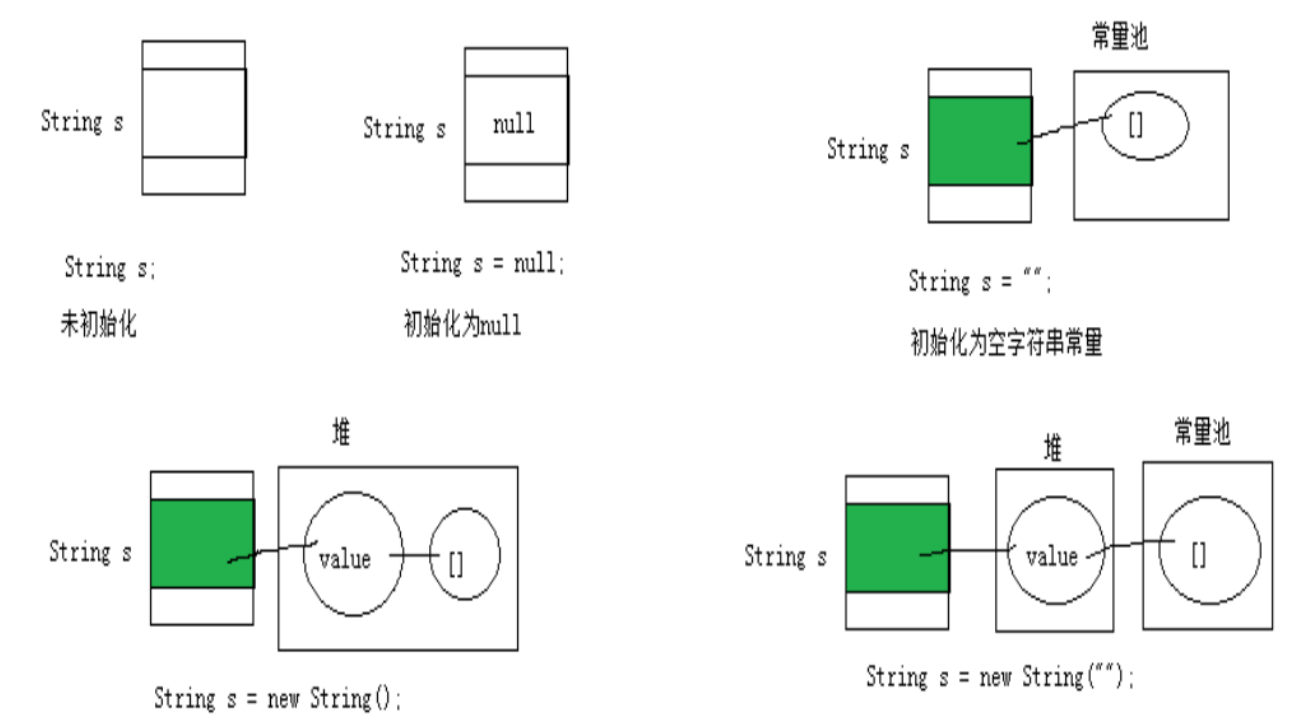
String str1 = “abc”;与String str2 = new String(“abc”);的区别?
- 字符串常量存储在字符串常量池,目的是共享
- 字符串非常量对象存储在堆中。
4、String不同拼接操作的对比
String使用陷阱
String s1 = “a”;
说明:在字符串常量池中创建了一个字面量为”a”的字符串。
s1 = s1 + “b”;
说明:实际上原来的“a”字符串对象已经丢弃了,现在在堆空间中产生了一个字符串s1+”b”(也就是”ab”)。如果多次执行这些改变串内容的操作,会导致大量副本字符串对象存留在内存中,降低效率。如果这样的操作放到循环中,会极大影响程序的性能。
String s2 = “ab”;
说明:直接在字符串常量池中创建一个字面量为”ab”的字符串。
String s3 = “a” + “b”;
说明:s3指向字符串常量池中已经创建的”ab”的字符串。
String s4 = s1.intern();
说明:堆空间的s1对象在调用intern()之后,会将常量池中已经存在的”ab”字符串赋值给s4。
5、一道面试题
1 | public class StringTest { |
6、JVM中涉及字符串的内存结构
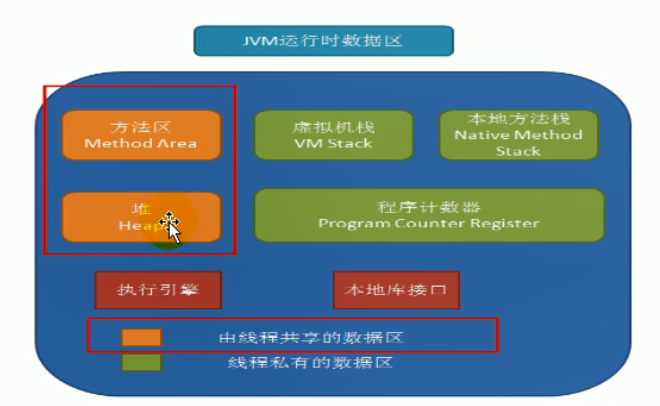






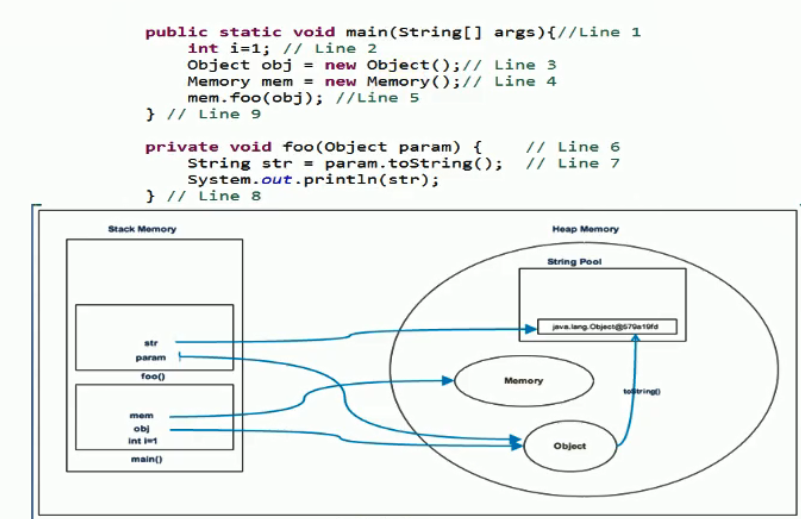
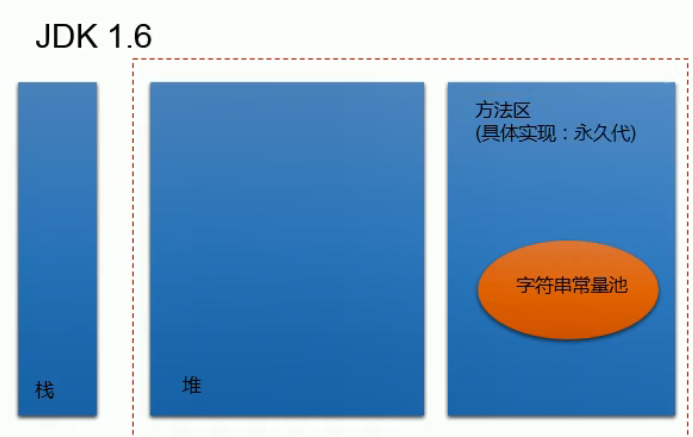


7、String常用的方法
1 | /** |
1 | /** |
1 | /** |
8.String与其他数据类型之间的转换
String–> int 使用 Integer.parseInt(str1);将字符串转换为数字
String –> char[]:调用String的toCharArray()
char[] –> String:调用String的构造器
String <—> byte
- 编码:String –> byte[]:调用String的getBytes()
- 解码:byte[] –> String:调用String的构造器
9、StringBuffer和StringBuilder的介绍
1 | /** |
10、StringBuffer的源码分析
1 | /** |
11、StringBuffer中的常用方法
1 | /** |
12、String、StringBuffer、StringBuilder效率对比 —–相比String,其他两个
1 | /** |
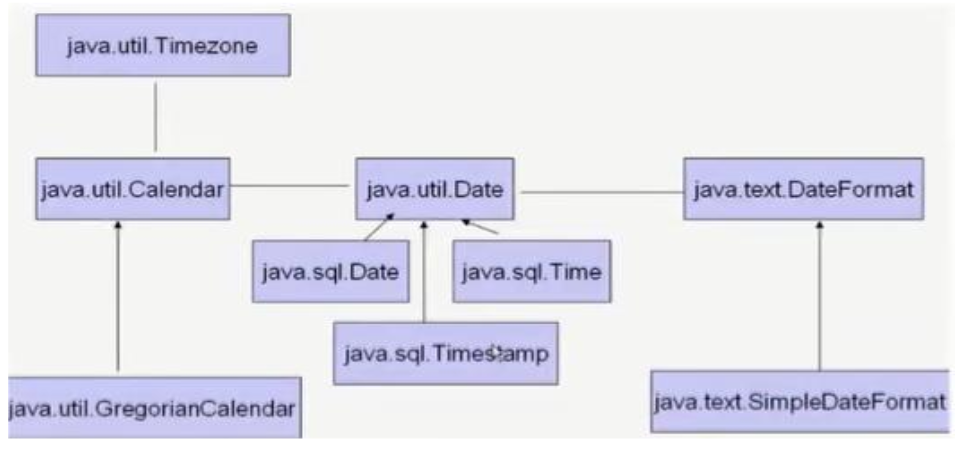
2、JDK 8之前的日期时间API
1、System类中获取时间戳的方法
System类提供的public static long currentTimeMillis()用来返回当前时间与1970年1月1日0时0分0秒之间以毫秒为单位的时间差。
- 此方法适于计算时间差。
- 计算世界时间的主要标准有:
- UTC(Coordinated Universal Time)
- GMT(Greenwich Mean Time)
- CST(Central Standard Time)
1 | long time = System.currentTimeMillis(); |
2、Java中两个Date类的使用
1 | import java.util.Date; |
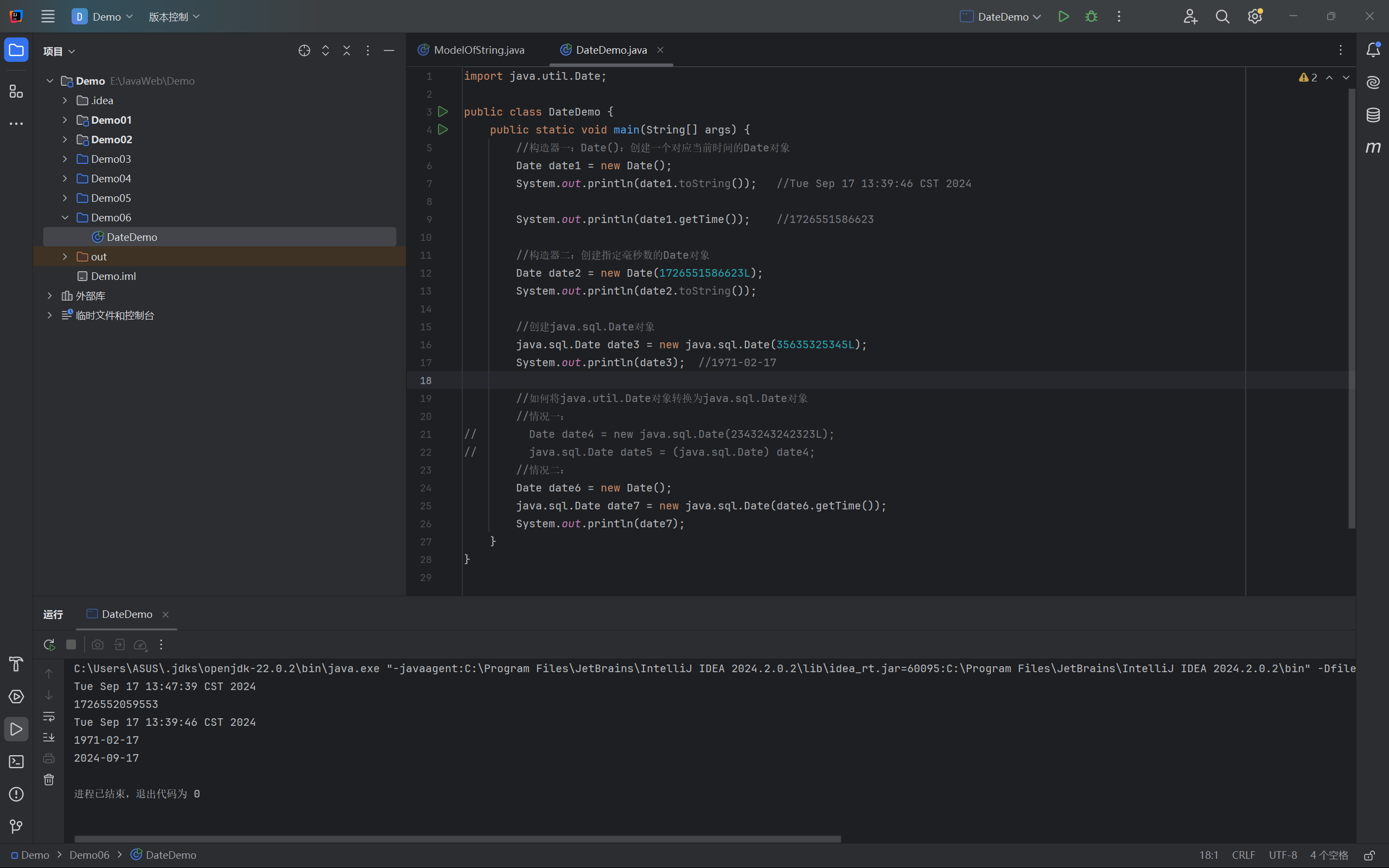
3、SimpleDateFormate的使用
- Date类的API不易于国际化,大部分被废弃了,java.text.SimpleDateFormat类是一个不与语言环境有关的方式来格式化和解析日期的具体类。
- 它允许进行
- 格式化:日期—>文本
- 解析:文本—>日期
- 主要用于对格式日期的读取,或者对日期进行自定义格式化
4、Calendar日历类的使用
- Calendar是一个抽象基类,主用用于完成日期字段之间相互操作的功能。
- 获取Calendar实例的方法
- 使用Calendar.getInstance()方法
- 调用它的子类GregorianCalendar的构造器。
- 一个Calendar的实例是系统时间的抽象表示,通过get(intfield)方法来取得想要的时间信息。比如YEAR、MONTH、DAY_OF_WEEK、HOUR_OF_DAY 、MINUTE、SECOND
- public void set(intfield,intvalue)
- public void add(intfield,intamount)
- public final Date getTime()
- public final void setTime(Date date)
- 注意:
- 获取月份时:一月是0,二月是1,以此类推,12月是11
- 获取星期时:周日是1,周二是2,。。。。周六是7
1 | import java.util.Calendar; |
3、JDK8中日期API的介绍
- 新日期时间API出现的背景
如果我们可以跟别人说:“我们在1502643933071见面,别晚了!”那么就再简单不过了。但是我们希望时间与昼夜和四季有关,于是事情就变复杂了。JDK 1.0中包含了一个java.util.Date类,但是它的大多数方法已经在JDK 1.1引入Calendar类之后被弃用了。而Calendar并不比Date好多少。它们面临的问题是:
可变性:像日期和时间这样的类应该是不可变的。
偏移性:Date中的年份是从1900开始的,而月份都从0开始。
格式化:格式化只对Date有用,Calendar则不行。
此外,它们也不是线程安全的;不能处理闰秒等。
总结:对日期和时间的操作一直是Java程序员最痛苦的地方之一。
- Java 8 吸收了Joda-Time 的精华,以一个新的开始为Java 创建优秀的API。新的java.time 中包含了所有关于本地日期(LocalDate)、本地时间(LocalTime)、本地日期时间(LocalDateTime)、时区(ZonedDateTime)和持续时间(Duration)的类。历史悠久的Date 类新增了toInstant() 方法,用于把Date 转换成新的表示形式。这些新增的本地化时间日期API 大大简化了日期时间和本地化的管理。
1 | java.time–包含值对象的基础包 |
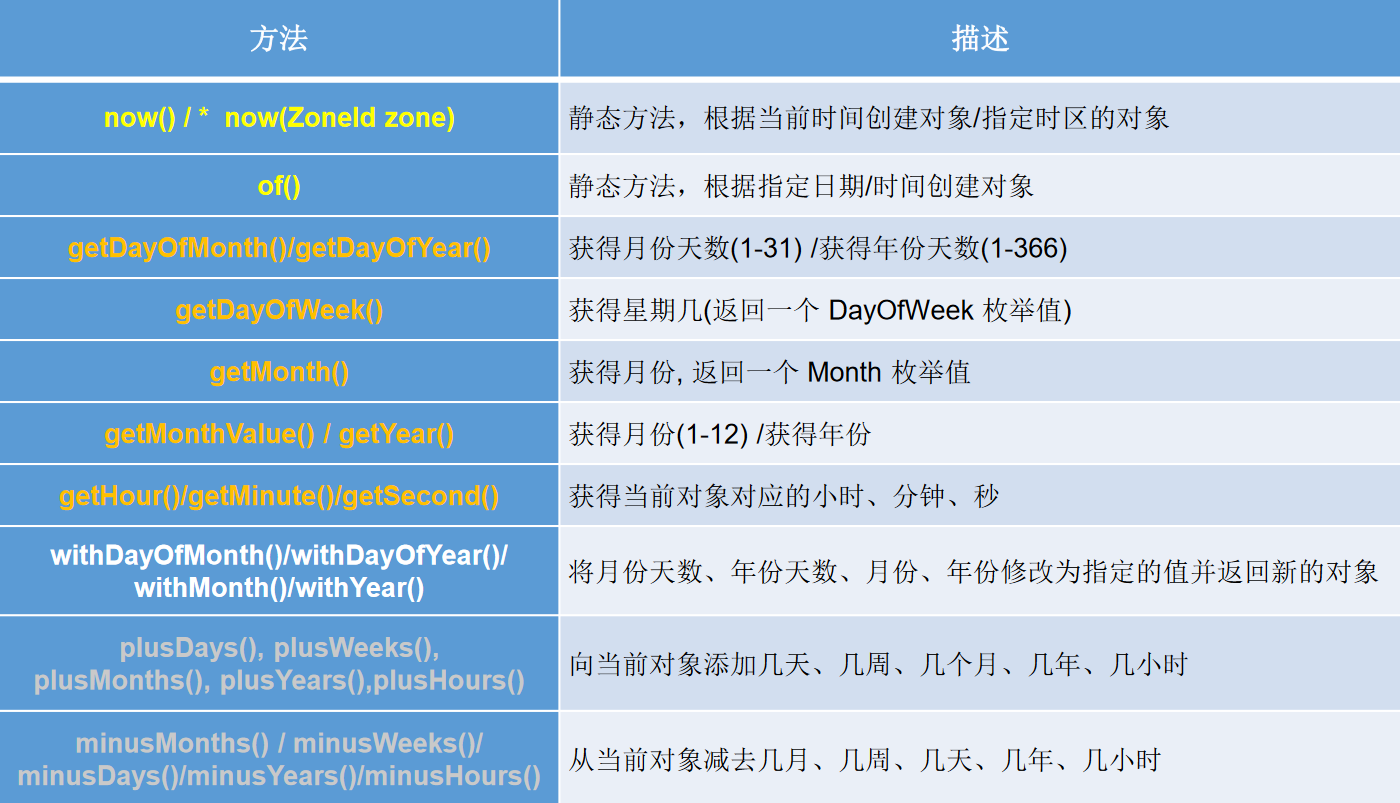
1.LocalDate、LocalTime、LocalDateTime的使用
LocalDate、LocalTime、LocalDateTime 类是其中较重要的几个类,它们的实例是不可变的对象,分别表示使用ISO-8601日历系统的日期、时间、日期和时间。它们提供了简单的本地日期或时间,并不包含当前的时间信息,也不包含与时区相关的信息。
- LocalDate代表IOS格式(yyyy-MM-dd)的日期,可以存储生日、纪念日等日期。
- LocalTime表示一个时间,而不是日期。
- LocalDateTime是用来表示日期和时间的,这是一个最常用的类之一。
注:ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法,也就是公历。
1 | import java.time.LocalDate; |
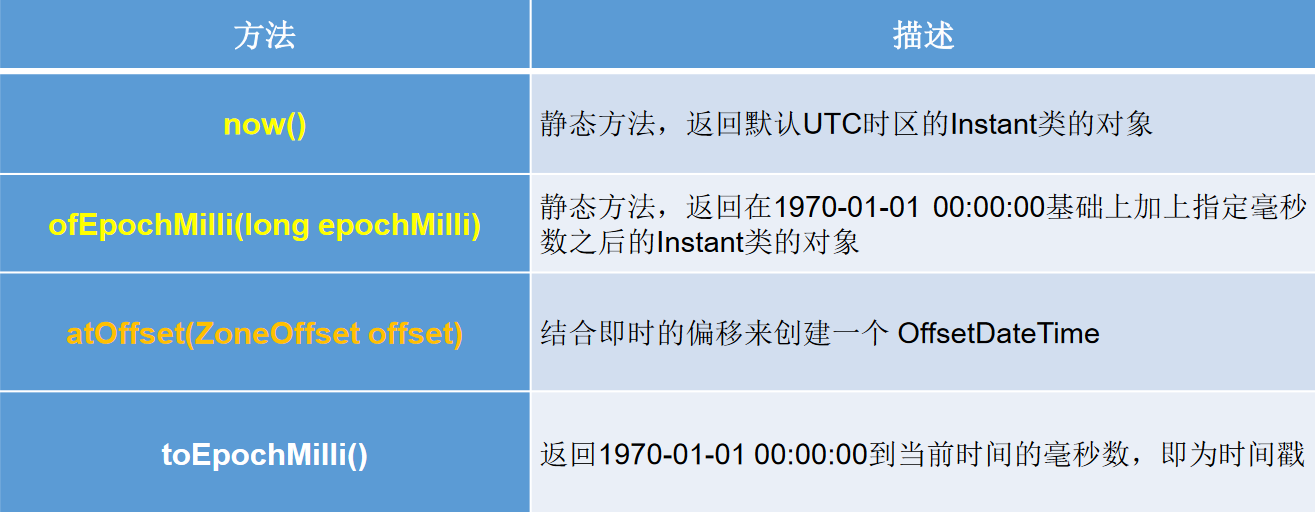
2、Instant类的使用
- Instant:时间线上的一个瞬时点。这可能被用来记录应用程序中的事件时间戳。
- 在处理时间和日期的时候,我们通常会想到年,月,日,时,分,秒。然而,这只是时间的一个模型,是面向人类的。第二种通用模型是面向机器的,或者说是连续的。在此模型中,时间线中的一个点表示为一个很大的数,这有利于计算机处理。在UNIX中,这个数从1970年开始,以秒为的单位;同样的,在Java中,也是从1970年开始,但以毫秒为单位。
- java.time包通过值类型Instant提供机器视图,不提供处理人类意义上的时间单位。Instant表示时间线上的一点,而不需要任何上下文信息,例如,时区。概念上讲,它只是简单的表示自1970年1月1日0时0分0秒(UTC)开始的秒数。因为java.time包是基于纳秒计算的,所以Instant的精度可以达到纳秒级。
- (1 ns = 10-9s) 1秒= 1000毫秒=10^6微秒=10^9纳秒
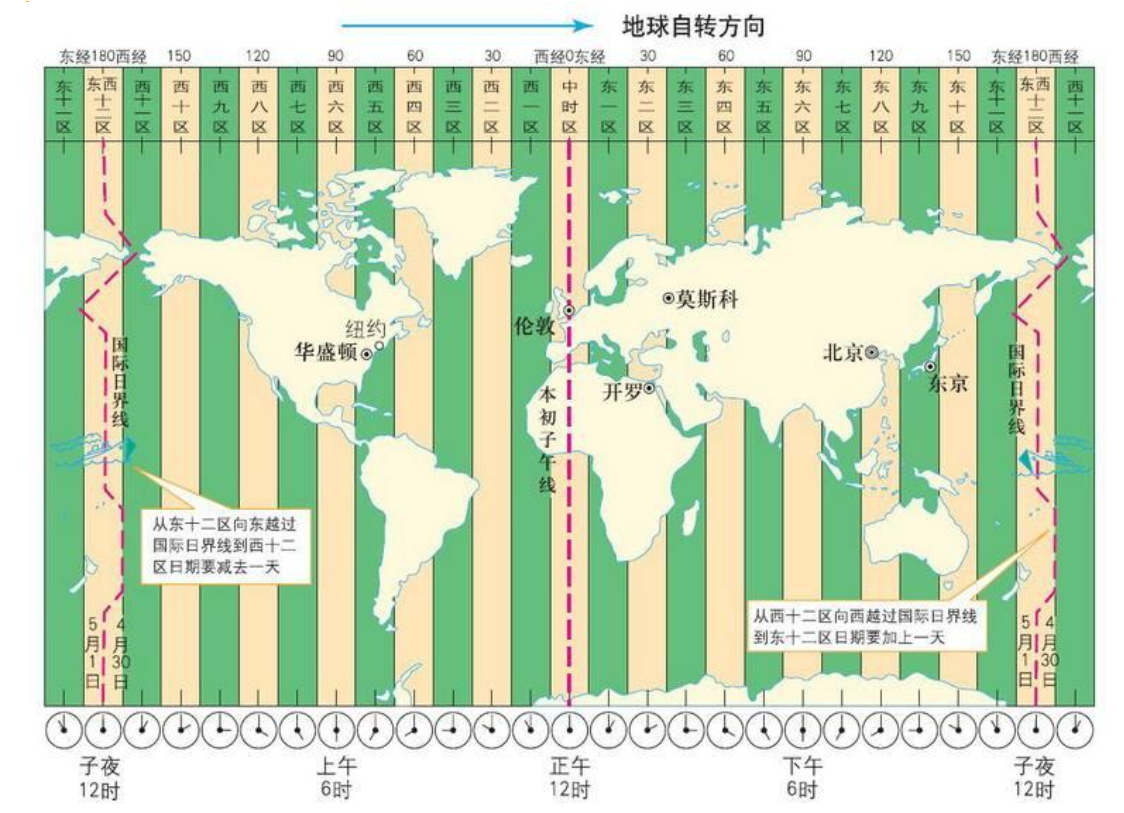
- 时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。
1 | import java.time.Instant; |
4、Java比较器
1.概述
2
3
4
5
* 一、说明:Java中的对象,正常情况下,只能进行比较:== 或 != 。不能使用 > 或 < 的
* 但是在开发场景中,我们需要对多个对象进行排序,言外之意,就需要比较对象的大小。
* 如何实现?使用两个接口中的任何一个:Comparable 或 Comparator
*/
Java实现对象排序的方式有两种:
- 自然排序:java.lang.Comparable
- 定制排序:java.util.Comparator
Comparable自然排序举例
1 | import java.util.Arrays; |
2、自定义类实现Comparable自然排序
1 | import java.util.Arrays; |
- Goods类
1 | public class Goods implements Comparable{ |
3、使用Comparator实现定制排序
1 | import org.junit.Test; |
- Comparable接口与Comparator的使用的对比:
- Comparable接口的方式一旦一定,保证Comparable接口实现类的对象在任何位置都可以比较大小。
- Comparator接口属于临时性的比较。
5、System类、Math类、BigInteger与BigDecimal
1、System类
System类代表系统,系统级的很多属性和控制方法都放置在该类的内部。该类位于java.lang包。
由于该类的构造器是private的,所以无法创建该类的对象,也就是无法实例化该类。其内部的成员变量和成员方法都是static的,所以也可以很方便的进行调用。
成员变量
- System类内部包含in、out和err三个成员变量,分别代表标准输入流(键盘输入),标准输出流(显示器)和标准错误输出流(显示器)。
成员方法
native long currentTimeMillis():
该方法的作用是返回当前的计算机时间,时间的表达格式为当前计算机时间和GMT时间(格林威治时间)1970年1月1号0时0分0秒所差的毫秒数。
void exit(int status):
该方法的作用是退出程序。其中status的值为0代表正常退出,非零代表异常退出。使用该方法可以在图形界面编程中实现程序的退出功能等。
void gc():
该方法的作用是请求系统进行垃圾回收。至于系统是否立刻回收,则取决于系统中垃圾回收算法的实现以及系统执行时的情况。String
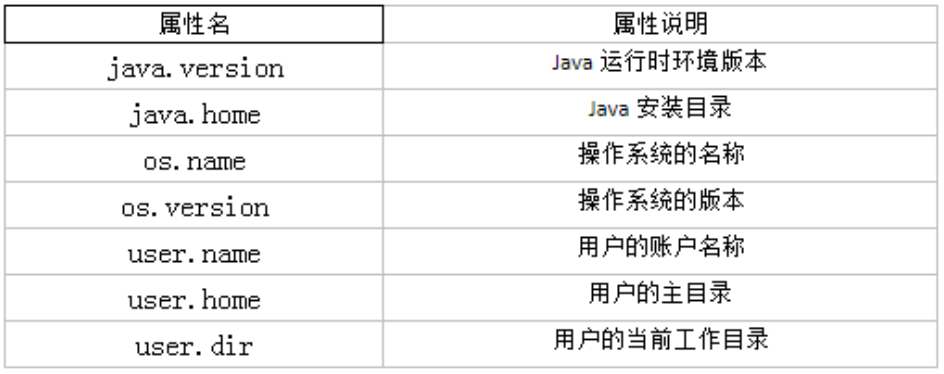
getProperty(String key):
该方法的作用是获得系统中属性名为key的属性对应的值。系统中常见的属性名以及属性的作用如下表所示:
1 | public class SystemDemo { |
2、Math类
- 这个在之前也简单使用过的
java.lang.Math提供了一系列静态方法用于科学计算。其方法的参数和返回值类型一般为double型。
abs 绝对值
acos,asin,atan,cos,sin,tan 三角函数
sqrt 平方根
pow(double a,doble b) a的b次幂
log 自然对数
exp e为底指数
max(double a,double b)
min(double a,double b)
random() 返回0.0到1.0的随机数
long round(double a) double型数据a转换为long型(四舍五入)
toDegrees(double angrad) 弧度—>角度
toRadians(double angdeg) 角度—>弧度
3、BigInteger与BigDecimal
Integer类作为int的包装类,能存储的最大整型值为2^31 -1,Long类也是有限的,最大为2^63 -1。如果要表示再大的整数,不管是基本数据类型还是他们的包装类都无能为力,更不用说进行运算了。
java.math包的BigInteger可以表示不可变的任意精度的整数。BigInteger 提供所有Java 的基本整数操作符的对应物,并提供java.lang.Math 的所有相关方法。另外,BigInteger 还提供以下运算:模算术、GCD 计算、质数测试、素数生成、位操作以及一些其他操作。
构造器
- BigInteger(String val):根据字符串构建BigInteger对象
常用方法

- 一般的Float类和Double类可以用来做科学计算或工程计算,但在商业计算中,要求数字精度比较高,故用到java.math.BigDecimal类。
- BigDecimal类支持不可变的、任意精度的有符号十进制定点数。
- 构造器
- public BigDecimal(double val)
- public BigDecimal(String val)
- 常用方法
- public BigDecimal add(BigDecimal augend)
- public BigDecimal subtract(BigDecimal subtrahend)
- public BigDecimal multiply(BigDecimal multiplicand)
- public BigDecimal divide(BigDecimal divisor, int scale, int roundingMode)
集合
1、Java集合框架概述
1、集合框架和数组的对比及概述
1 | /** |
集合的使用场景
2、集合框架涉及到的API
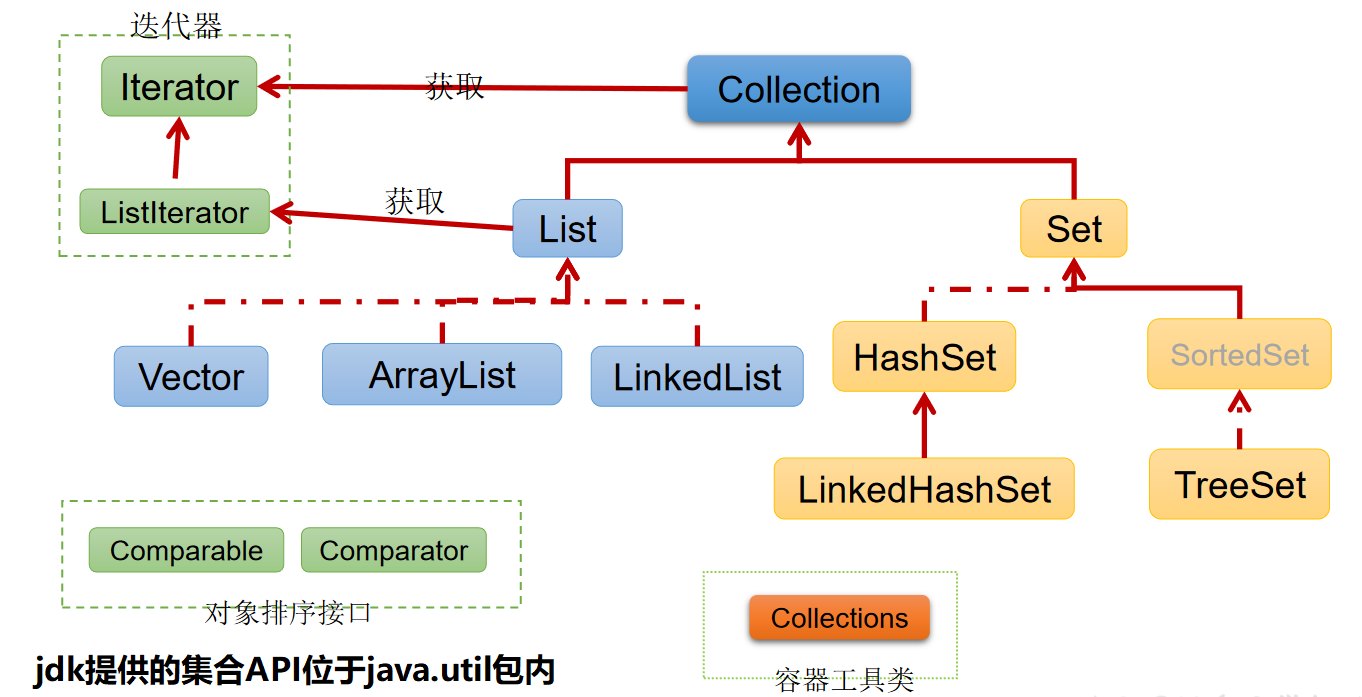
Java 集合可分为Collection 和Map 两种体系
- Collection接口:单列数据,定义了存取一组对象的方法的集合
- List:元素有序、可重复的集合
- Set:元素无序、不可重复的集合
- Map接口:双列数据,保存具有映射关系“key-value对”的集合
- Collection接口:单列数据,定义了存取一组对象的方法的集合
Collection接口继承树
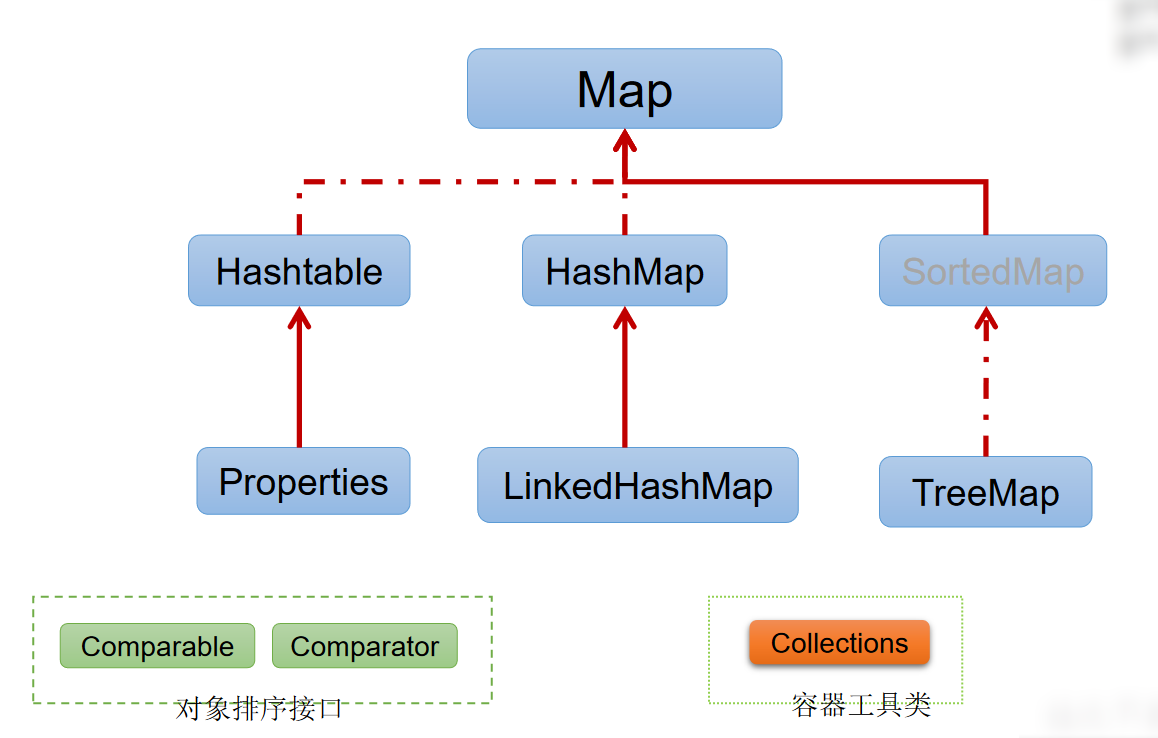
- Map接口继承树
1 | /** |
2、Collection接口方法
- Collection 接口是List、Set 和Queue 接口的父接口,该接口里定义的方法既可用于操作Set 集合,也可用于操作List 和Queue 集合。
- JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List)实现。
- 在Java5 之前,Java 集合会丢失容器中所有对象的数据类型,把所有对象都当成Object 类型处理;从JDK 5.0 增加了泛型以后,Java 集合可以记住容器中对象的数据类型。
Collection接口中的常用方法
- 添加
- add(Objectobj)
- addAll(Collectioncoll)
- 获取有效元素的个数
- intsize()
- 清空集合
- voidclear()
- 是否是空集合
- boolean isEmpty()
- 是否包含某个元素
- booleancontains(Objectobj):是通过元素的equals方法来判断是否是同一个对象
- booleancontainsAll(Collectionc):也是调用元素的equals方法来比较的。拿两个集合的元素挨个比较。
- 删除
- boolean remove(Object obj) :通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素
- boolean removeAll(Collection coll):取当前集合的差集
- 取两个集合的交集
- boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c
- 集合是否相等
- boolean equals(Object obj)
- 转成对象数组
- Object[] toArray()
- 获取集合对象的哈希值
- hashCode()
- 遍历
- iterator():返回迭代器对象,用于集合遍历
1 | import java.util.ArrayList; |
3.Iterator迭代器接口
- Iterator对象称为迭代器(设计模式的一种),主要用于遍历Collection 集合中的元素。
- GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。类似于“公交车上的售票员”、“火车上的乘务员”、“空姐”。
- Collection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象。
- Iterator 仅用于遍历集合,Iterator本身并不提供承装对象的能力。如果需要创建Iterator 对象,则必须有一个被迭代的集合。
- 集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
1 | import java.util.ArrayList; |
迭代器Iterator的执行原理

Iterator迭代器remove()的使用
1 | import org.junit.Test; |
- 注意:
- Iterator可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove方法,不是集合对象的remove方法。
- 如果还未调用next()或在上一次调用next方法之后已经调用了remove方法,再调用remove都会报IllegalStateException。
新特性foreach循环遍历集合或数组
- Java 5.0 提供了foreach循环迭代访问Collection和数组。
- 遍历操作不需获取Collection或数组的长度,无需使用索引访问元素。
- 遍历集合的底层调用Iterator完成操作。
- foreach还可以用来遍历数组。
4、Collection子接口之一:List接口
4.Collection子接口之一:List接口
- 鉴于Java中数组用来存储数据的局限性,我们通常使用List替代数组
- List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。
- List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
- JDK API中List接口的实现类常用的有:ArrayList、LinkedList和Vector。
List接口常用实现类的对比
1 | /** |
ArrayList的源码分析
- ArrayList是List 接口的典型实现类、主要实现类
- 本质上,ArrayList是对象引用的一个”变长”数组
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
* 2.ArrayList的源码分析:
* 2.1 jdk 7情况下
* ArrayList list = new ArrayList();//底层创建了长度是10的Object[]数组elementData
* list.add(123);//elementData[0] = new Integer(123);
* ...
* list.add(11);//如果此次的添加导致底层elementData数组容量不够,则扩容。
* 默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中。
*
* 结论:建议开发中使用带参的构造器:ArrayList list = new ArrayList(int capacity)
*
* 2.2 jdk 8中ArrayList的变化:
* ArrayList list = new ArrayList();//底层Object[] elementData初始化为{}.并没有创建长度为10的数组
*
* list.add(123);//第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到elementData[0]
* ...
* 后续的添加和扩容操作与jdk 7 无异。
* 2.3 小结:jdk7中的ArrayList的对象的创建类似于单例的饿汉式,而jdk8中的ArrayList的对象
* 的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
*
*/
LinkedList的源码分析
对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高
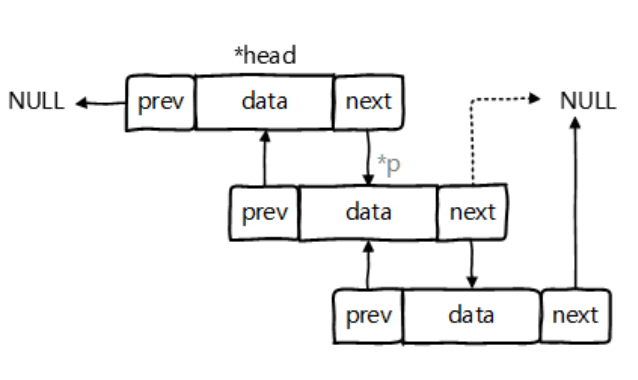
LinkedList:双向链表,内部没有声明数组,而是定义了Node类型的first和last,用于记录首末元素。同时,定义内部类Node,作为LinkedList中保存数据的基本结构。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
* 3.LinkedList的源码分析:
* LinkedList list = new LinkedList(); 内部声明了Node类型的first和last属性,默认值为null
* list.add(123);//将123封装到Node中,创建了Node对象。
*
* 其中,Node定义为:体现了LinkedList的双向链表的说法
* private static class Node<E> {
* E item;
* Node<E> next;
* Node<E> prev;
*
* Node(Node<E> prev, E element, Node<E> next) {
* this.item = element;
* this.next = next; //next变量记录下一个元素的位置
* this.prev = prev; //prev变量记录前一个元素的位置
* }
* }
*/
Vector的源码分析
- Vector 是一个古老的集合,JDK1.0就有了。大多数操作与ArrayList相同,区别之处在于Vector是线程安全的。
- 在各种list中,最好把ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList;Vector总是比ArrayList慢,所以尽量避免使用。
2
3
4
* 4.Vector的源码分析:jdk7和jdk8中通过Vector()构造器创建对象时,底层都创建了长度为10的数组。
* 在扩容方面,默认扩容为原来的数组长度的2倍。
*/
List接口中的常用方法测试
- List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
- void add(intindex, Object ele):在index位置插入ele元素
- boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
- Object get(int index):获取指定index位置的元素
- int indexOf(Object obj):返回obj在集合中首次出现的位置
- int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
- Object remove(int index):移除指定index位置的元素,并返回此元素
- Object set(int index, Object ele):设置指定index位置的元素为ele
- List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
1 | // 5.List接口的常用方法 |
List的一个面试题
- 面试题1
请问ArrayList/LinkedList/Vector的异同?谈谈你的理解?ArrayList底层是什么?扩容机制?Vector和ArrayList的最大区别?
1 | /** |
5、Collection子接口之二:Set接口
- Set接口是Collection的子接口,set接口没有提供额外的方法
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败。
- Set 判断两个对象是否相同不是使用== 运算符,而是根据equals() 方法
Set接口实现类的对比
2
3
4
5
6
7
8
9
* 1.Set接口的框架:
* |----Collection接口:单列集合,用来存储一个一个的对象
* |----Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”
* |----HashSet:作为Set接口的主要实现类;线程不安全的;可以存储null值
* |----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历
* 对于频繁的遍历操作,LinkedHashSet效率高于HashSet.
* |----TreeSet:可以按照添加对象的指定属性,进行排序。
*
HashSet中元素的添加过程
HashSet是Set 接口的典型实现,大多数时候使用Set 集合时都使用这个实现类。
HashSet按Hash 算法来存储集合中的元素,因此具有很好的存取、查找、删除性能。
HashSet具有以下特点:不能保证元素的排列顺序
- HashSet不是线程安全的
- 集合元素可以是null
HashSet 集合判断两个元素相等的标准:两个对象通过hashCode() 方法比较相等,并且两个对象的equals() 方法返回值也相等。
对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
* 一、Set:存储无序的、不可重复的数据
* 1.无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。
*
* 2.不可重复性:保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一个。
*
* 二、添加元素的过程:以HashSet为例:
* 我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,
* 此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断
* 数组此位置上是否已经有元素:
* 如果此位置上没有其他元素,则元素a添加成功。 --->情况1
* 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
* 如果hash值不相同,则元素a添加成功。--->情况2
* 如果hash值相同,进而需要调用元素a所在类的equals()方法:
* equals()返回true,元素a添加失败
* equals()返回false,则元素a添加成功。--->情况2
*
* 对于添加成功的情况2和情况3而言:元素a 与已经存在指定索引位置上数据以链表的方式存储。
* jdk 7 :元素a放到数组中,指向原来的元素。
* jdk 8 :原来的元素在数组中,指向元素a
* 总结:七上八下
*
* HashSet底层:数组+链表的结构。
*
*/
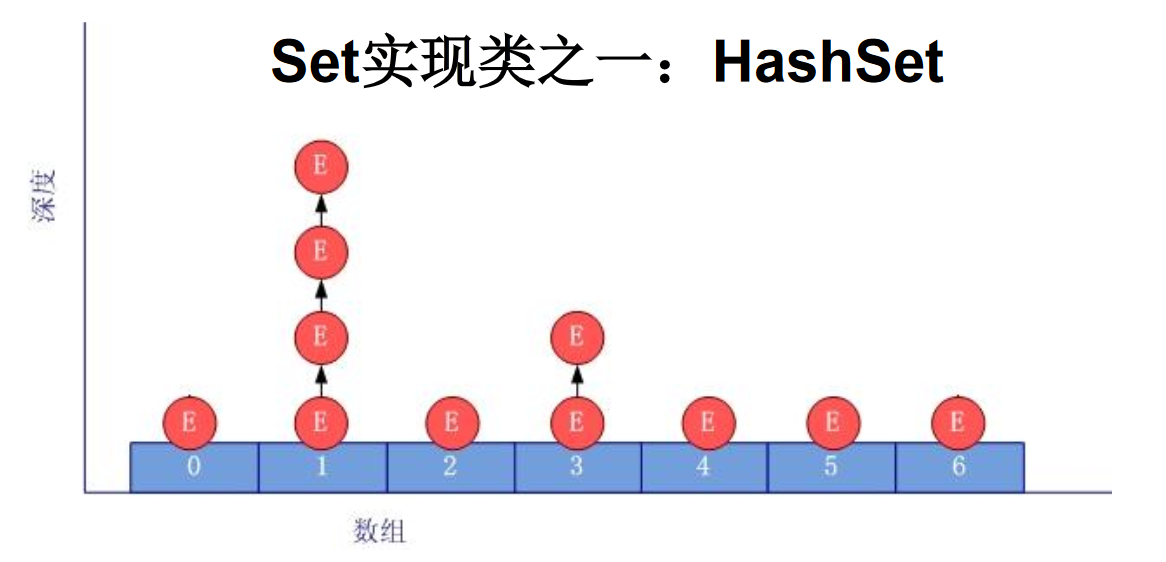
底层也是数组,初始容量为16,当如果使用率超过0.75,(16*0.75=12)就会扩大容量为原来的2倍。(16扩容为32,依次为64,128….等)
关于hashCode()和equals()的重写
重写hashCode() 方法的基本原则
- 在程序运行时,同一个对象多次调用hashCode() 方法应该返回相同的值。
- 当两个对象的equals() 方法比较返回true 时,这两个对象的hashCode() 方法的返回值也应相等。
- 对象中用作equals() 方法比较的Field,都应该用来计算hashCode 值。
重写equals() 方法的基本原则
以自定义的Customer类为例,何时需要重写equals()?
- 当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是要改写hashCode(),根据一个类的equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode()方法,它们仅仅是两个对象。
- 因此,违反了“相等的对象必须具有相等的散列码”。
- 结论:复写equals方法的时候一般都需要同时复写hashCode方法。通常参与计算hashCode的对象的属性也应该参与到equals()中进行计算。
Eclipse/IDEA工具里hashCode()的重写
以Eclipse/IDEA为例,在自定义类中可以调用工具自动重写equals和hashCode。问题:为什么用Eclipse/IDEA复写hashCode方法,有31这个数字?
- 选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
- 并且31只占用5bits,相乘造成数据溢出的概率较小。
- 31可以由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化。(提高算法效率)
- 31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除!(减少冲突)
2
3
4
5
* 2.要求:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()
* 要求:重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
* 重写两个方法的小技巧:对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
*/
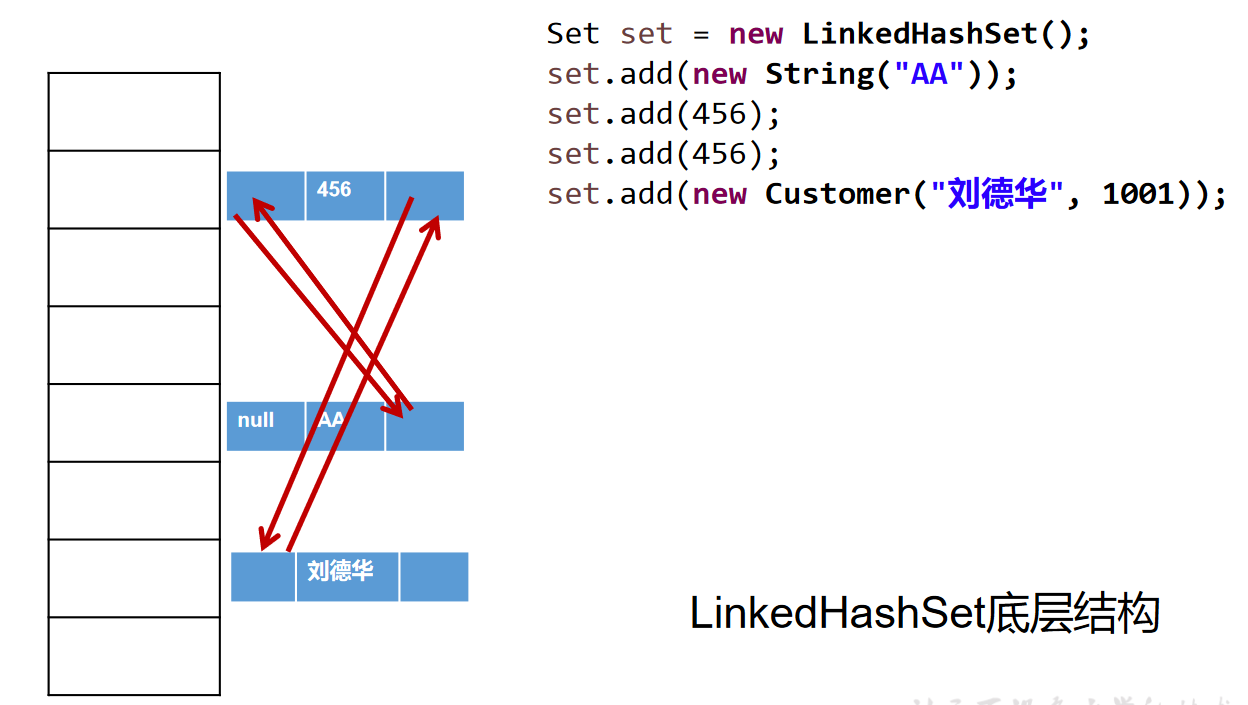
LinkedHashSet的使用
- LinkedHashSet是HashSet的子类
- LinkedHashSet根据元素的hashCode值来决定元素的存储位置,但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
- LinkedHashSet插入性能略低于HashSet,但在迭代访问Set 里的全部元素时有很好的性能。
- LinkedHashSet不允许集合元素重复。
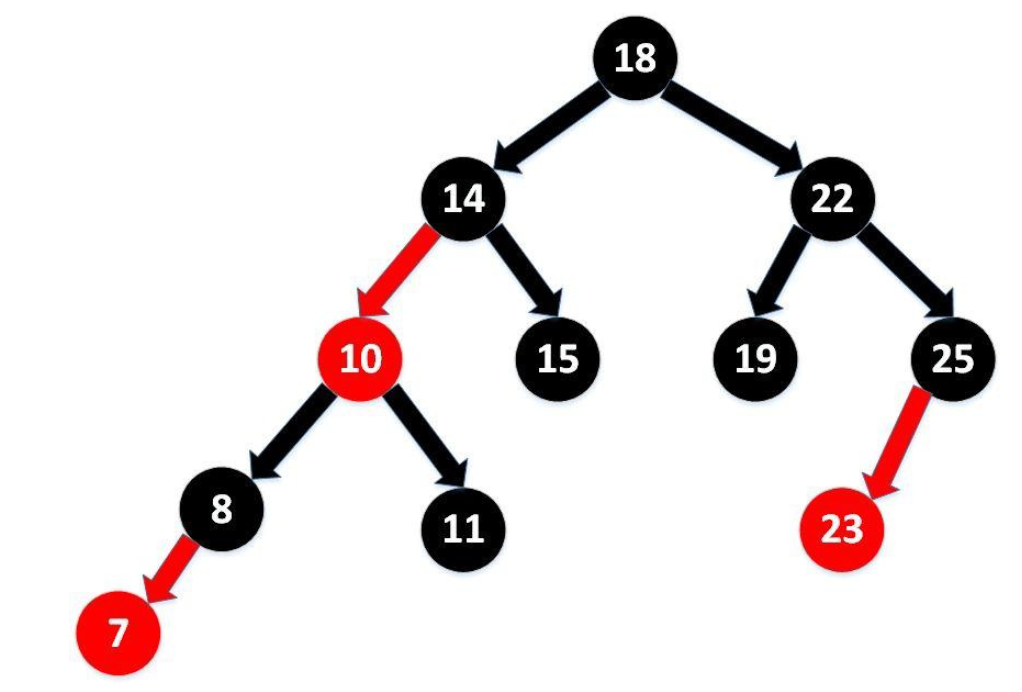
TreeSet的自然排序
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。
TreeSet底层使用红黑树结构存储数据
新增的方法如下:(了解)
- Comparator comparator()
- Object first()
- Object last()
- Object lower(Object e)
- Object higher(Object e)
- SortedSet subSet(fromElement, toElement)
- SortedSet headSet(toElement)
- SortedSet tailSet(fromElement)
TreeSet两种排序方法:自然排序和定制排序。默认情况下,TreeSet采用自然排序。
TreeSet和后面要讲的TreeMap采用红黑树的存储结构
特点:有序,查询速度比List快
自然排序:TreeSet会调用集合元素的compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列。
如果试图把一个对象添加到TreeSet时,则该对象的类必须实现Comparable 接口。
- 实现Comparable 的类必须实现compareTo(Object obj) 方法,两个对象即通过compareTo(Object obj) 方法的返回值来比较大小。
Comparable 的典型实现:
- BigDecimal、BigInteger 以及所有的数值型对应的包装类:按它们对应的数值大小进行比较
- Character:按字符的unicode值来进行比较
- Boolean:true 对应的包装类实例大于false 对应的包装类实例
- String:按字符串中字符的unicode 值进行比较
- Date、Time:后边的时间、日期比前面的时间、日期大
向TreeSet中添加元素时,只有第一个元素无须比较compareTo()方法,后面添加的所有元素都会调用compareTo()方法进行比较。
因为只有相同类的两个实例才会比较大小,所以向TreeSet中添加的应该是同一个类的对象。
对于TreeSet集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj) 方法比较返回值。
当需要把一个对象放入TreeSet中,重写该对象对应的equals() 方法时,应保证该方法与compareTo(Object obj) 方法有一致的结果:如果两个对象通过equals() 方法比较返回true,则通过compareTo(Object obj) 方法比较应返回0。否则,让人难以理解。
TreeSet的定制排序
- TreeSet的自然排序要求元素所属的类实现Comparable接口,如果元素所属的类没有实现Comparable接口,或不希望按照升序(默认情况)的方式排列元素或希望按照其它属性大小进行排序,则考虑使用定制排序。定制排序,通过Comparator接口来实现。需要重写compare(T o1,T o2)方法。
- 利用int compare(T o1,T o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2。
- 要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器。
- 此时,仍然只能向TreeSet中添加类型相同的对象。否则发生ClassCastException异常。
- 使用定制排序判断两个元素相等的标准是:通过Comparator比较两个元素返回了0。
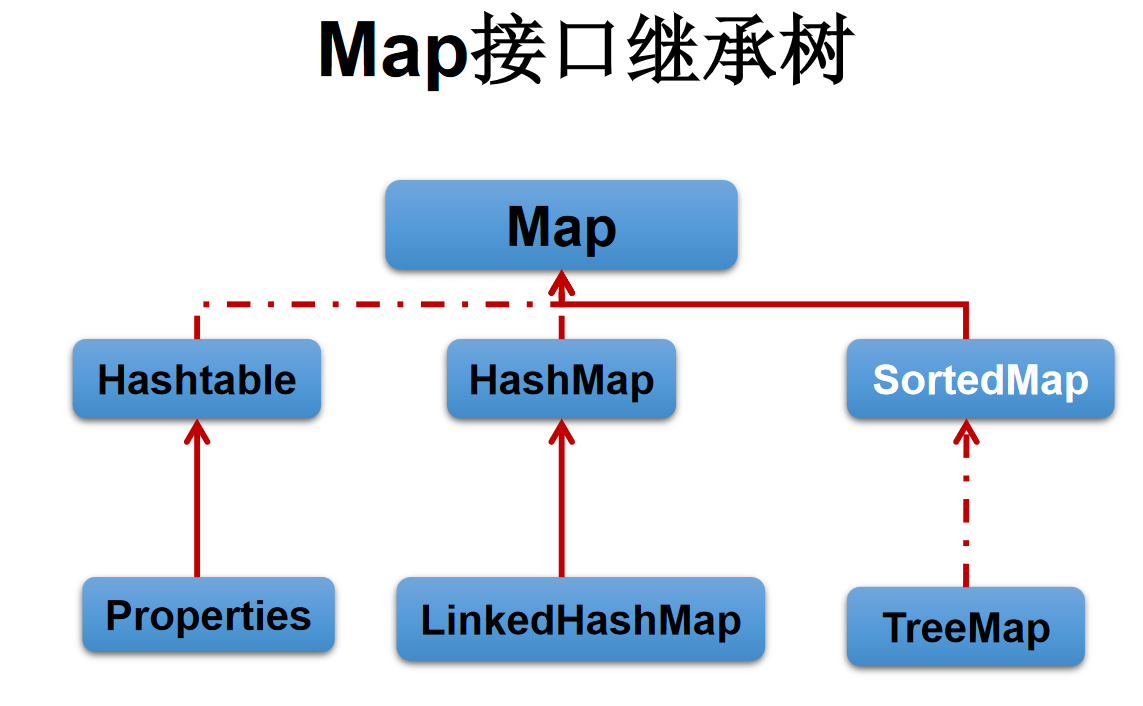
6、Map接口
Map中存储的key-value的特点
- Map与Collection并列存在。用于保存具有映射关系的数据:key-value
- Map 中的key 和value 都可以是任何引用类型的数据
- Map 中的key 用Set来存放,不允许重复,即同一个Map 对象所对应的类,须重写hashCode()和equals()方法
- 常用String类作为Map的“键”
- key 和value 之间存在单向一对一关系,即通过指定的key 总能找到唯一的、确定的value
- Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中,HashMap是Map 接口使用频率最高的实现类
1 | /** |
Map实现类之一:HashMap
- HashMap是Map 接口使用频率最高的实现类。
- 允许使用null键和null值,与HashSet一样,不保证映射的顺序。
- 所有的key构成的集合是Set:无序的、不可重复的。所以,key所在的类要重写:equals()和hashCode()
- 所有的value构成的集合是Collection:无序的、可以重复的。所以,value所在的类要重写:equals()
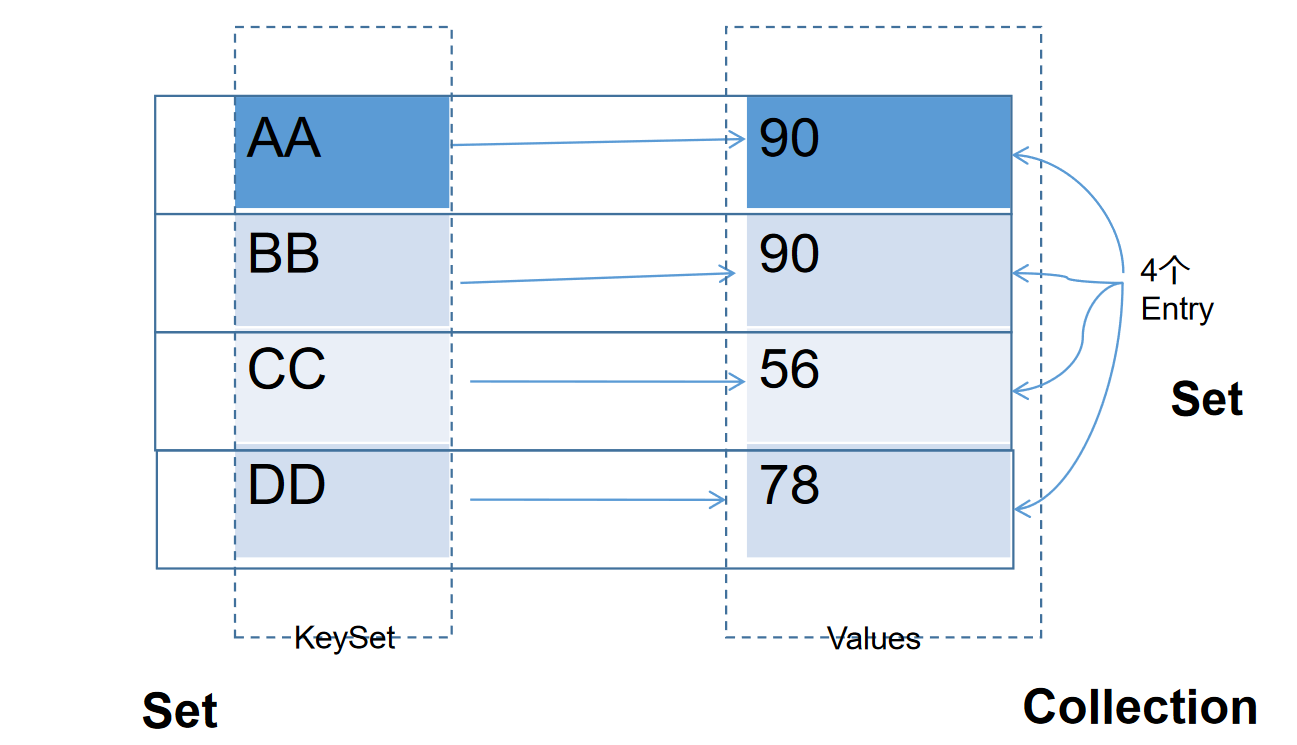
- 一个key-value构成一个entry
- 所有的entry构成的集合是Set:无序的、不可重复的
- HashMap 判断两个key 相等的标准是:两个key 通过equals() 方法返回true,hashCode值也相等。
- HashMap判断两个value相等的标准是:两个value 通过equals() 方法返回true。
HashMap的底层实现原理
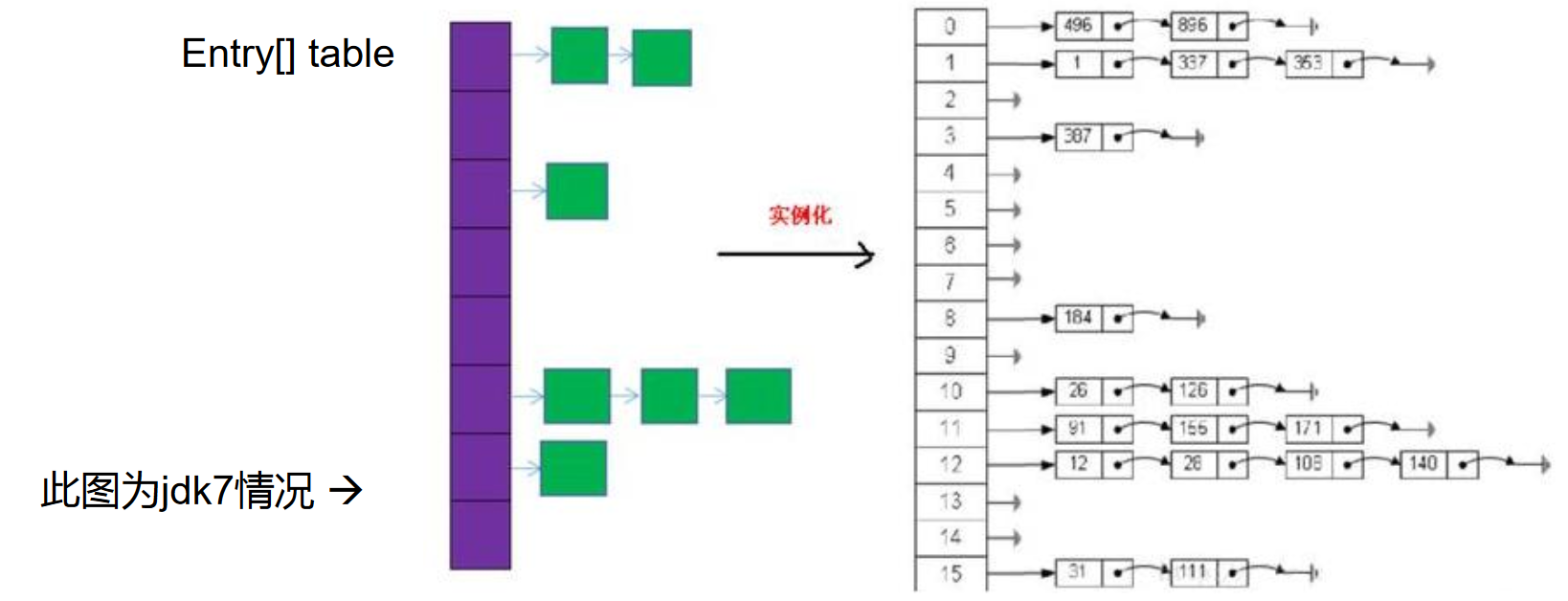
JDK 7及以前版本:HashMap是数组+链表结构(即为链地址法)
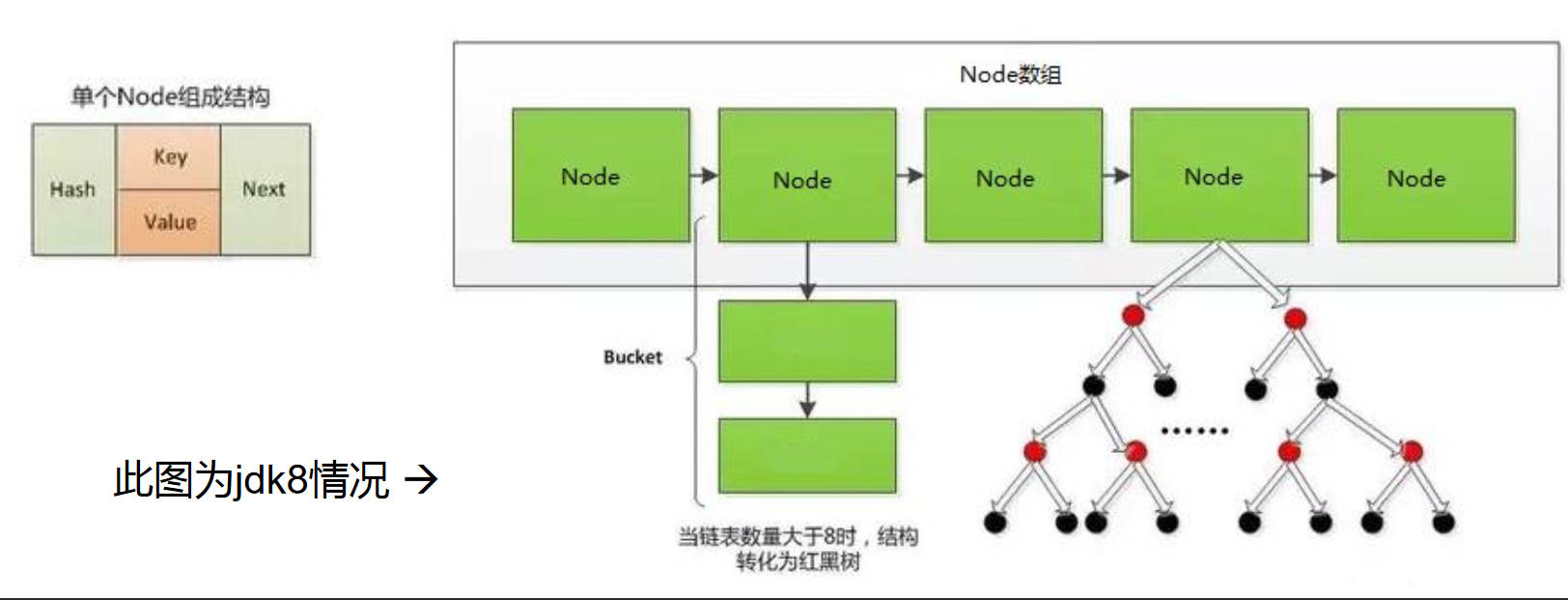
JDK 8版本发布以后:HashMap是数组+链表+红黑树实现。
- HashMap源码中的重要常量
1 | /* |
HashMap在JDK7中的底层实现原理
- HashMap的内部存储结构其实是数组和链表的结合。当实例化一个HashMap时,系统会创建一个长度为Capacity的Entry数组,这个长度在哈希表中被称为容量(Capacity),在这个数组中可以存放元素的位置我们称之为“桶”(bucket),每个bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。
- 每个bucket中存储一个元素,即一个Entry对象,但每一个Entry对象可以带一个引用变量,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Entry链。而且新添加的元素作为链表的head。
- 添加元素的过程:
- 向HashMap中添加entry1(key,value),需要首先计算entry1中key的哈希值(根据key所在类的hashCode()计算得到),此哈希值经过处理以后,得到在底层Entry[]数组中要存储的位置i。如果位置i上没有元素,则entry1直接添加成功。如果位置i上已经存在entry2(或还有链表存在的entry3,entry4),则需要通过循环的方法,依次比较entry1中key和其他的entry。如果彼此hash值不同,则直接添加成功。如果hash值不同,继续比较二者是否equals。如果返回值为true,则使用entry1的value去替换equals为true的entry的value。如果遍历一遍以后,发现所有的equals返回都为false,则entry1仍可添加成功。entry1指向原有的entry元素。
1 | /* |
1 | /** |
HashMap在JDK8中的底层实现原理
HashMap的内部存储结构其实是数组+链表+树的结合。当实例化一个HashMap时,会初始化initialCapacity和loadFactor,在put第一对映射关系时,系统会创建一个长度为initialCapacity的Node数组,这个长度在哈希表中被称为容量(Capacity),在这个数组中可以存放元素的位置我们称之为“桶”(bucket),每个bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。
每个bucket中存储一个元素,即一个Node对象,但每一个Node对象可以带一个引用变量next,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Node链。也可能是一个一个TreeNode对象,每一个TreeNode对象可以有两个叶子结点left和right,因此,在一个桶中,就有可能生成一个TreeNode树。而新添加的元素作为链表的last,或树的叶子结点。
那么HashMap什么时候进行扩容和树形化呢?
当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数size)loadFactor时,就会进行数组扩容,loadFactor的默认值(DEFAULT_LOAD_FACTOR)为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小(DEFAULT_INITIAL_CAPACITY)为16,那么当HashMap中元素个数超过160.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
当HashMap中的其中一个链的对象个数如果达到了8个,此时如果capacity没有达到64,那么HashMap会先扩容解决,如果已经达到了64,那么这个链会变成树,结点类型由Node变成TreeNode类型。当然,如果当映射关系被移除后,下次resize方法时判断树的结点个数低于6个,也会把树再转为链表。
关于映射关系的key是否可以修改?answer:不要修改
映射关系存储到HashMap中会存储key的hash值,这样就不用在每次查找时重新计算每一个Entry或Node(TreeNode)的hash值了,因此如果已经put到Map中的映射关系,再修改key的属性,而这个属性又参与hashcode值的计算,那么会导致匹配不上。
1 | /* 总结: |
LinkedHashMap的底层实现原理(了解!!!)
LinkedHashMap是HashMap的子类
在HashMap存储结构的基础上,使用了一对双向链表来记录添加元素的顺序
与LinkedHashSet类似,LinkedHashMap可以维护Map 的迭代顺序:迭代顺序与Key-Value 对的插入顺序一致
HashMap中的内部类:Node
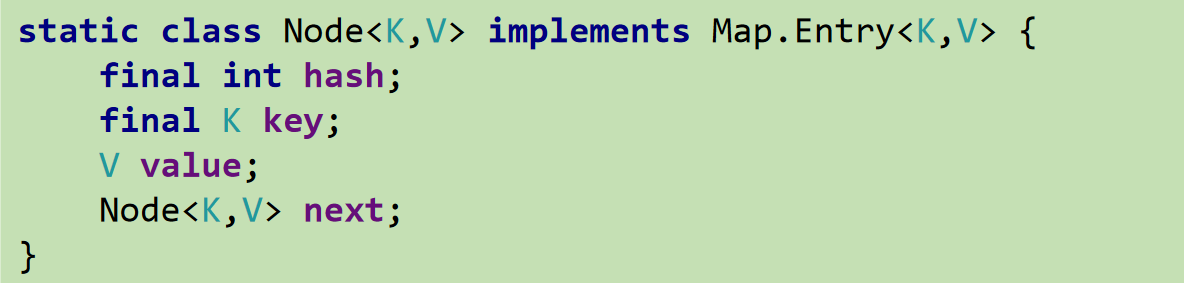
- LinkedHashMap中的内部类:Entry

Map中的常用方法
1 | /** |
TreeMap两种添加方式的使用
- TreeMap存储Key-Value 对时,需要根据key-value 对进行排序。TreeMap可以保证所有的Key-Value 对处于有序状态。
- TreeSet底层使用红黑树结构存储数据
- TreeMap的Key 的排序:
- 自然排序:TreeMap的所有的Key 必须实现Comparable 接口,而且所有的Key 应该是同一个类的对象,否则将会抛出ClasssCastException
- 定制排序:创建TreeMap时,传入一个Comparator 对象,该对象负责对TreeMap中的所有key 进行排序。此时不需要Map 的Key 实现Comparable 接口
- TreeMap判断两个key相等的标准:两个key通过compareTo()方法或者compare()方法返回0。
Hashtable
- Hashtable是个古老的Map 实现类,JDK1.0就提供了。不同于HashMap,Hashtable是线程安全的。
- Hashtable实现原理和HashMap相同,功能相同。底层都使用哈希表结构,查询速度快,很多情况下可以互用。
- 与HashMap不同,Hashtable不允许使用null 作为key 和value
- 与HashMap一样,Hashtable也不能保证其中Key-Value 对的顺序
- Hashtable判断两个key相等、两个value相等的标准,与HashMap一致。
Properties处理属性文件
- Properties 类是Hashtable的子类,该对象用于处理属性文件
- 由于属性文件里的key、value 都是字符串类型,所以Properties 里的key 和value 都是字符串类型
- 存取数据时,建议使用setProperty(String key,Stringvalue)方法和getProperty(String key)方法
7、Collections工具类
操作数组的工具类:Arrays
Collections 是一个操作Set、List和Map 等集合的工具类
Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法
排序操作:(均为static方法)
- reverse(List):反转List 中元素的顺序
- shuffle(List):对List集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定List 集合元素按升序排序
- sort(List,Comparator):根据指定的Comparator 产生的顺序对List 集合元素进行排序
- swap(List,int,int):将指定list 集合中的i处元素和j 处元素进行交换
IO
1、File类的使用
File类的实例化
- java.io.File类:文件和文件目录路径的抽象表示形式,与平台无关
- File 能新建、删除、重命名文件和目录,但File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
- 想要在Java程序中表示一个真实存在的文件或目录,那么必须有一个File对象,但是Java程序中的一个File对象,可能没有一个真实存在的文件或目录。
- File对象可以作为参数传递给流的构造器
1 | /** |
File类的常用方法
1 | /** |
2.IO流原理及流的分类
IO流原理
- I/O是Input/Output的缩写,I/O技术是非常实用的技术,用于处理设备之间的数据传输。如读/写文件,网络通讯等。
- Java程序中,对于数据的输入/输出操作以“流(stream)”的方式进行。
- java.io包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据。
- 输入input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
- 输出output:将程序(内存)数据输出到磁盘、光盘等存储设备中。
流的分类
- 按操作数据单位不同分为:字节流(8 bit),字符流(16 bit)
- 按数据流的流向不同分为:输入流,输出流
- 按流的角色的不同分为:节点流,处理流
| 抽象基类 | 字节流 | 字符流 |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Writer |
Java的IO流共涉及40多个类,实际上非常规则,都是从如下4个抽象基类派生的。
由这四个类派生出来的子类名称都是以其父类名作为子类名后缀。
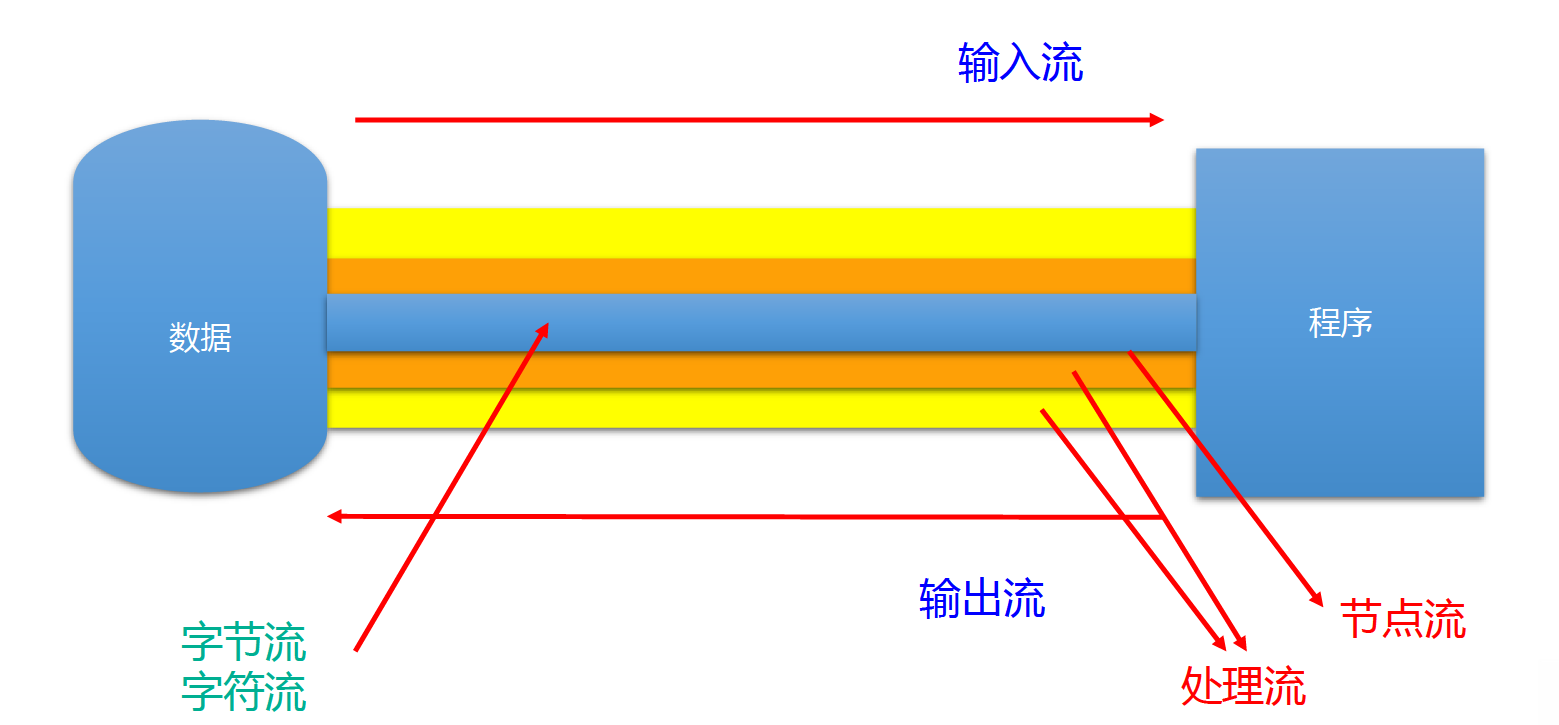
IO 流体系
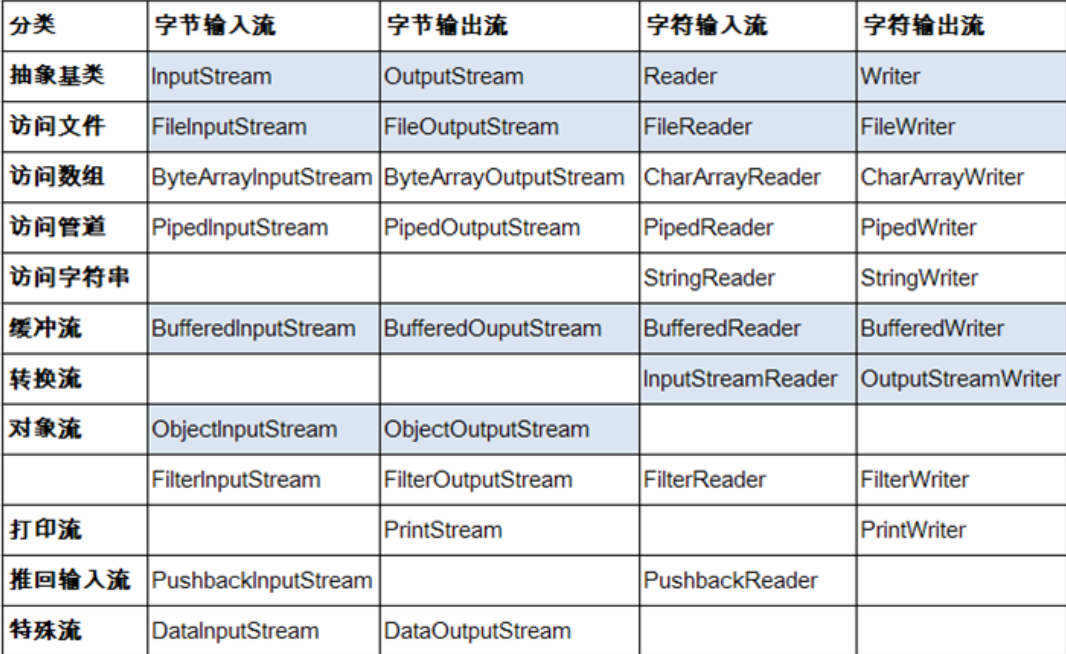
3.节点流(或文件流)
FileReader读入数据的基本操作
- 读取文件
1 | 1.建立一个流对象,将已存在的一个文件加载进流。 |
FileWriter写出数据的操作
- 写入文件
1 | 1.创建流对象,建立数据存放文件 |
4.缓冲流
- 为了提高数据读写的速度,Java API提供了带缓冲功能的流类,在使用这些流类时,会创建一个内部缓冲区数组,缺省使用8192个字节(8Kb)的缓冲区。
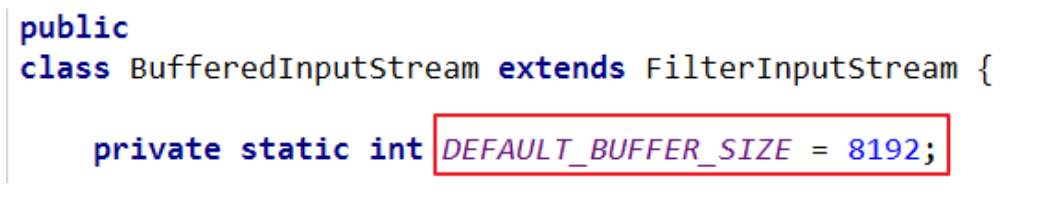
缓冲流要“套接”在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
- BufferedInputStream和BufferedOutputStream
- BufferedReader和BufferedWriter
当读取数据时,数据按块读入缓冲区,其后的读操作则直接访问缓冲区
当使用BufferedInputStream读取字节文件时,BufferedInputStream会一次性从文件中读取8192个(8Kb),存在缓冲区中,直到缓冲区装满了,才重新从文件中读取下一个8192个字节数组。
向流中写入字节时,不会直接写到文件,先写到缓冲区中直到缓冲区写满,BufferedOutputStream才会把缓冲区中的数据一次性写到文件里。使用方法flush()可以强制将缓冲区的内容全部写入输出流
关闭流的顺序和打开流的顺序相反。只要关闭最外层流即可,关闭最外层流也会相应关闭内层节点流
flush()方法的使用:手动将buffer中内容写入文件
如果是带缓冲区的流对象的close()方法,不但会关闭流,还会在关闭流之前刷新缓冲区,关闭后不能再写出。
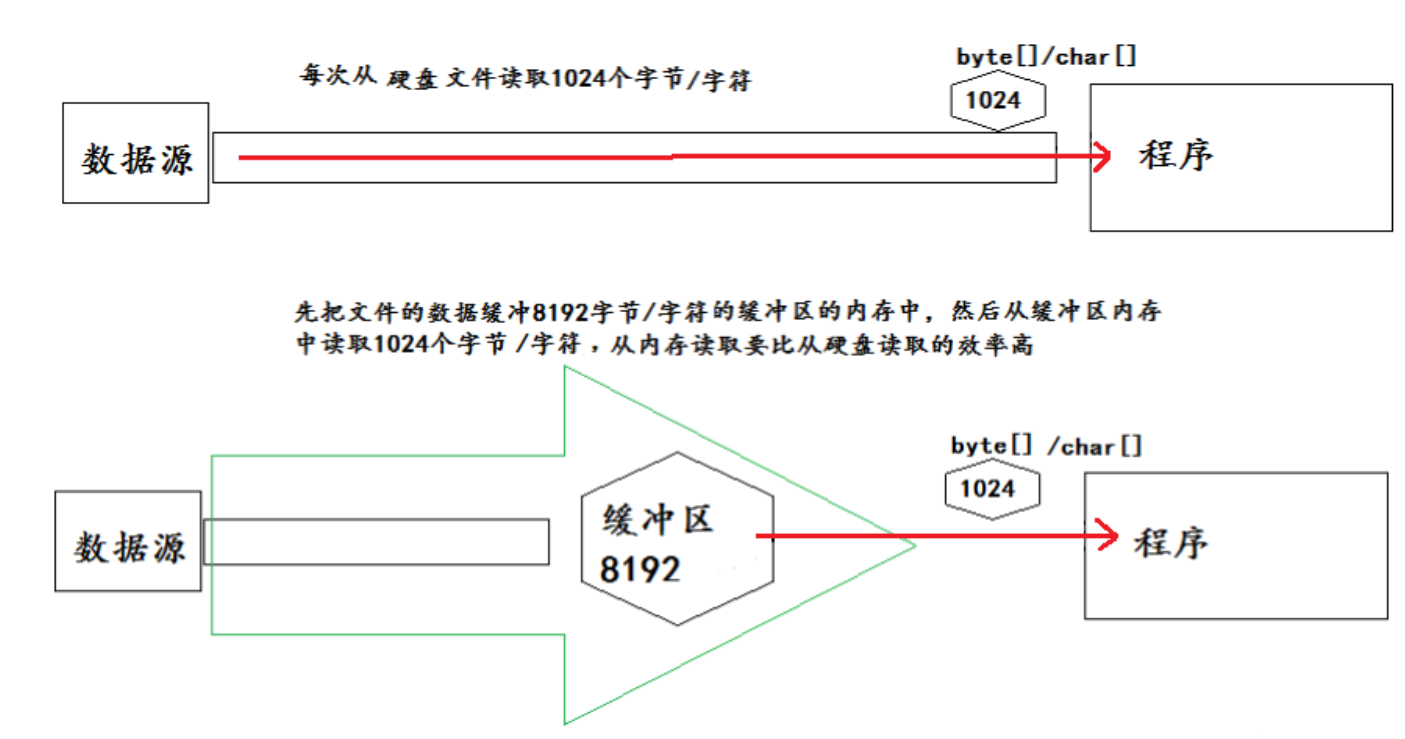
5.转换流
转换流概述与InputStreamReader的使用
转换流提供了在字节流和字符流之间的转换
Java API提供了两个转换流:
- InputStreamReader:将InputStream转换为Reader
- 实现将字节的输入流按指定字符集转换为字符的输入流。
- 需要和InputStream“套接”。
- 构造器
- public InputStreamReader(InputStreamin)
- public InputSreamReader(InputStreamin,StringcharsetName)
- 如:Reader isr= new InputStreamReader(System.in,”gbk”);
- OutputStreamWriter:将Writer转换为OutputStream
- 实现将字符的输出流按指定字符集转换为字节的输出流。
- 需要和OutputStream“套接”。
- 构造器
- public OutputStreamWriter(OutputStreamout)
- public OutputSreamWriter(OutputStreamout,StringcharsetName)
- InputStreamReader:将InputStream转换为Reader
字节流中的数据都是字符时,转成字符流操作更高效。
很多时候我们使用转换流来处理文件乱码问题。实现编码和解码的功能。
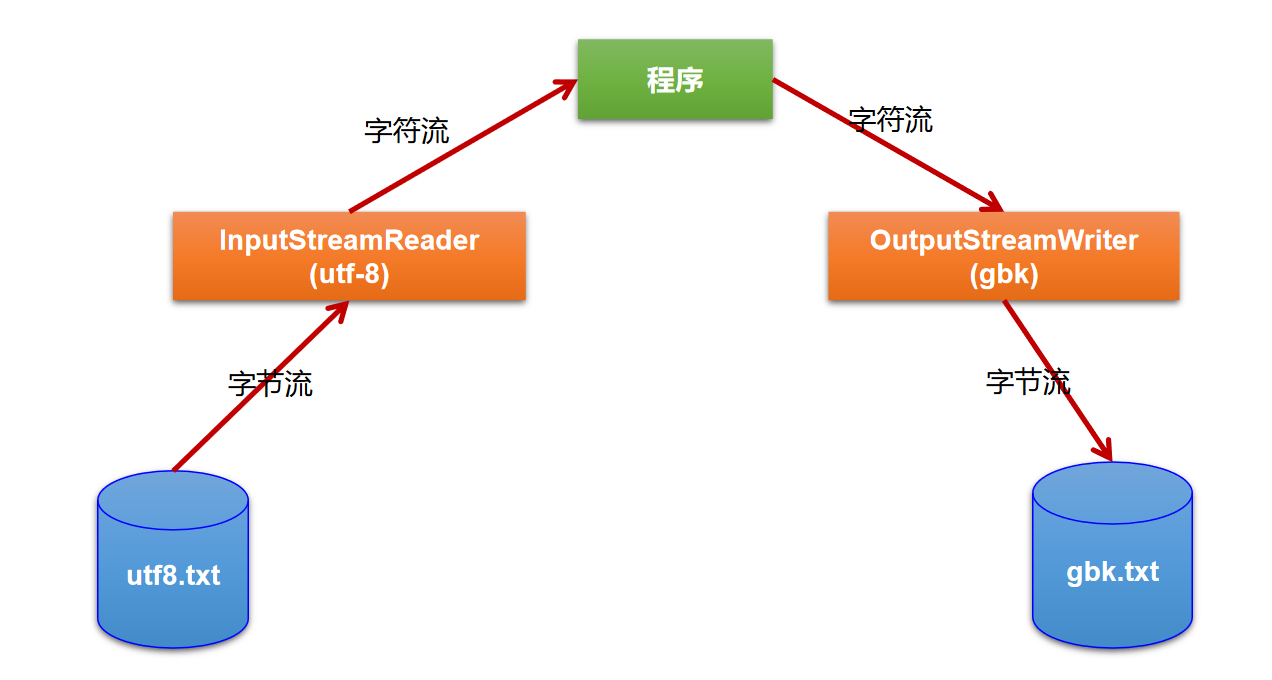
多种字符编码集的说明
编码表的由来
计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字。就将各个国家的文字用数字来表示,并一一对应,形成一张表。这就是编码表。
常见的编码表
1 | /** |
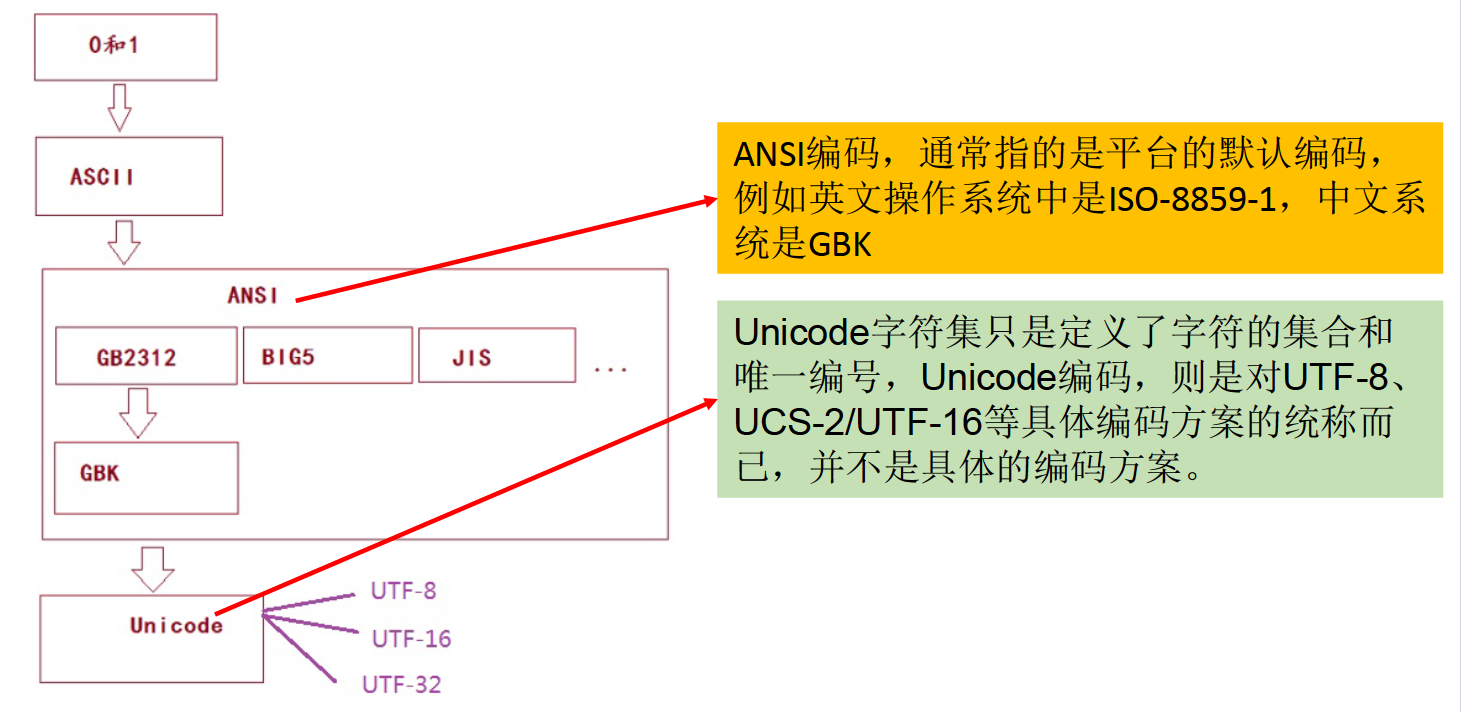
- Unicode不完美,这里就有三个问题,一个是,我们已经知道,英文字母只用一个字节表示就够了,第二个问题是如何才能区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢?第三个,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,不够表示所有字符。Unicode在很长一段时间内无法推广,直到互联网的出现。
- 面向传输的众多UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
- Unicode只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。推荐的Unicode编码是UTF-8和UTF-16。

6.标准输入、输出流
- System.in和System.out分别代表了系统标准的输入和输出设备
- 默认输入设备是:键盘,输出设备是:显示器
- System.in的类型是InputStream
- System.out的类型是PrintStream,其是OutputStream的子类FilterOutputStream的子类
- 重定向:通过System类的setIn,setOut方法对默认设备进行改变。
- public static void setIn(InputStreamin)
- public static void setOut(PrintStreamout)
7.打印流
- 实现将基本数据类型的数据格式转化为字符串输出
- 打印流:PrintStream和PrintWriter
- 提供了一系列重载的print()和println()方法,用于多种数据类型的输出
- PrintStream和PrintWriter的输出不会抛出IOException异常
- PrintStream和PrintWriter有自动flush功能
- PrintStream 打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用PrintWriter 类。
- System.out返回的是PrintStream的实例
8.数据流
为了方便地操作Java语言的基本数据类型和String的数据,可以使用数据流。
数据流有两个类:(用于读取和写出基本数据类型、String类的数据)
- DataInputStream和DataOutputStream
- 分别“套接”在InputStream和OutputStream子类的流上
DataInputStream中的方法
1
2
3
4
5boolean readBoolean() byte readByte()
char readChar() float readFloat()
double readDouble() short readShort()
long readLong() int readInt()
String readUTF() void readFully(byte[s] b)DataOutputStream中的方法
- 将上述的方法的read改为相应的write即可。
9.对象流
对象序列化机制的理解
- ObjectInputStream和OjbectOutputSteam
- 用于存储和读取基本数据类型数据或对象的处理流。它的强大之处就是可以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
- 序列化:用ObjectOutputStream类保存基本类型数据或对象的机制
- 反序列化:用ObjectInputStream类读取基本类型数据或对象的机制
- ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量
- 对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。//当其它程序获取了这种二进制流,就可以恢复成原来的Java对象
- 序列化的好处在于可将任何实现了Serializable接口的对象转化为字节数据,使其在保存和传输时可被还原
- 序列化是RMI(Remote Method Invoke –远程方法调用)过程的参数和返回值都必须实现的机制,而RMI 是JavaEE的基础。因此序列化机制是JavaEE平台的基础
- 如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现如下两个接口之一。否则,会抛出NotSerializableException异常
- Serializable
- Externalizable
自定义类实现序列化与反序列化操作
若某个类实现了Serializable接口,该类的对象就是可序列化的:
- 创建一个ObjectOutputStream
- 调用ObjectOutputStream对象的writeObject(对象) 方法输出可序列化对象
- 注意写出一次,操作flush()一次
反序列化
- 创建一个ObjectInputStream调用readObject() 方法读取流中的对象
强调:如果某个类的属性不是基本数据类型或String 类型,而是另一个引用类型,那么这个引用类型必须是可序列化的,否则拥有该类型的Field 的类也不能序列化
Person类
serialVersionUID的理解
凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量:
- private static final long serialVersionUID;
- serialVersionUID用来表明类的不同版本间的兼容性。简言之,其目的是以序列化对象进行版本控制,有关各版本反序列化时是否兼容。
- 如果类没有显示定义这个静态常量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的实例变量做了修改,serialVersionUID可能发生变化。故建议,显式声明。
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。(InvalidCastException)
Person类
10.随机存取文件流
RandomAccessFile 声明在java.io包下,但直接继承于java.lang.Object类。并且它实现了DataInput、DataOutput这两个接口,也就意味着这个类既可以读也可以写。
RandomAccessFile 类支持“随机访问” 的方式,程序可以直接跳到文件的任意地方来读、写文件
- 支持只访问文件的部分内容
- 可以向已存在的文件后追加内容
RandomAccessFile 对象包含一个记录指针,用以标示当前读写处的位置。RandomAccessFile类对象可以自由移动记录指针:
- long getFilePointer():获取文件记录指针的当前位置
- void seek(long pos):将文件记录指针定位到pos位置
构造器
- public RandomAccessFile(Filefile, Stringmode)
- public RandomAccessFile(Stringname, Stringmode)
创建RandomAccessFile类实例需要指定一个mode 参数,该参数指定RandomAccessFile的访问模式:
- r: 以只读方式打开
- rw:打开以便读取和写入
- rwd:打开以便读取和写入;同步文件内容的更新
- rws:打开以便读取和写入;同步文件内容和元数据的更新
如果模式为只读r。则不会创建文件,而是会去读取一个已经存在的文件,如果读取的文件不存在则会出现异常。如果模式为rw读写。如果文件不存在则会去创建文件,如果存在则不会创建。
11.NIO.2中Path、Paths、Files类的使用
Java NIO (New IO,Non-Blocking IO)是从Java 1.4版本开始引入的一套新的IO API,可以替代标准的Java IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的(IO是面向流的)、基于通道的IO操作。NIO将以更加高效的方式进行文件的读写操作。
Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
1
2
3
4
5|-----java.nio.channels.Channel
|-----FileChannel:处理本地文件
|-----SocketChannel:TCP网络编程的客户端的Channel
|-----ServerSocketChannel:TCP网络编程的服务器端的Channel
|-----DatagramChannel:UDP网络编程中发送端和接收端的Channel随着JDK 7 的发布,Java对NIO进行了极大的扩展,增强了对文件处理和文件系统特性的支持,以至于我们称他们为NIO.2。因为NIO 提供的一些功能,NIO已经成为文件处理中越来越重要的部分。
早期的Java只提供了一个File类来访问文件系统,但File类的功能比较有限,所提供的方法性能也不高。而且,大多数方法在出错时仅返回失败,并不会提供异常信息。
NIO. 2为了弥补这种不足,引入了Path接口,代表一个平台无关的平台路径,描述了目录结构中文件的位置。Path可以看成是File类的升级版本,实际引用的资源也可以不存在。
在以前IO操作都是这样写的:
- import java.io.File;
- File file = new File(“index.html”);
但在Java7 中,我们可以这样写:
- import java.nio.file.Path;
- import java.nio.file.Paths;
- Path path = Paths.get(“index.html”);
同时,NIO.2在java.nio.file包下还提供了Files、Paths工具类,Files包含了大量静态的工具方法来操作文件;Paths则包含了两个返回Path的静态工厂方法。
Paths 类提供的静态get() 方法用来获取Path 对象:
- static Pathget(String first, String … more) : 用于将多个字符串串连成路径
- static Path get(URI uri): 返回指定uri对应的Path路径
Path接口
- Files 类


一些对于NIO与IO的对比
作者:终端研发部
链接:https://www.zhihu.com/question/439681246/answer/1753604983
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
NIO是为了弥补IO操作的不足而诞生的,NIO的一些新特性有:非阻塞I/O,选择器,缓冲以及管道。管道(Channel),缓冲(Buffer) ,选择器( Selector)是其主要特征。
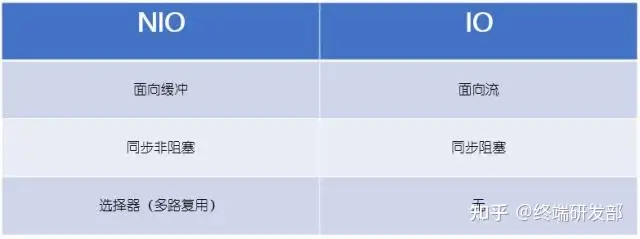
概念解释:
Channel——管道实际上就像传统IO中的流,到任何目的地(或来自任何地方)的所有数据都必须通过一个 Channel 对象。一个 Buffer 实质上是一个容器对象。
Selector——选择器用于监听多个管道的事件,使用传统的阻塞IO时我们可以方便的知道什么时候可以进行读写,而使用非阻塞通道,我们需要一些方法来知道什么时候通道准备好了,选择器正是为这个需要而诞生的。
NIO和传统的IO有什么区别呢?
1,IO是面向流的,NIO是面向块(缓冲区)的。
IO面向流的操作一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。,导致了数据的读取和写入效率不佳;
NIO面向块的操作在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多,同时数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。通俗来说,NIO采取了“预读”的方式,当你读取某一部分数据时,他就会猜测你下一步可能会读取的数据而预先缓冲下来。
2,IO是阻塞的,NIO是非阻塞的。
对于传统的IO,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
而对于NIO,使用一个线程发送读取数据请求,没有得到响应之前,线程是空闲的,此时线程可以去执行别的任务,而不是像IO中那样只能等待响应完成。
3,NIO和IO适用场景
NIO是为弥补传统IO的不足而诞生的,但是尺有所短寸有所长,NIO也有缺点,因为NIO是面向缓冲区的操作,每一次的数据处理都是对缓冲区进行的,那么就会有一个问题,在数据处理之前必须要判断缓冲区的数据是否完整或者已经读取完毕,如果没有,假设数据只读取了一部分,那么对不完整的数据处理没有任何意义。所以每次数据处理之前都要检测缓冲区数据。
那么NIO和IO各适用的场景是什么呢?
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,这时候用NIO处理数据可能是个很好的选择。
而如果只有少量的连接,而这些连接每次要发送大量的数据,这时候传统的IO更合适。使用哪种处理数据,需要在数据的响应等待时间和检查缓冲区数据的时间上作比较来权衡选择。
4,通俗解释
最后,对于NIO和传统IO,有一个网友讲的生动的例子:
以前的流总是堵塞的,一个线程只要对它进行操作,其它操作就会被堵塞,也就相当于水管没有阀门,你伸手接水的时候,不管水到了没有,你就都只能耗在接水(流)上。
nio的Channel的加入,相当于增加了水龙头(有阀门),虽然一个时刻也只能接一个水管的水,但依赖轮换策略,在水量不大的时候,各个水管里流出来的水,都可以得到妥
善接纳,这个关键之处就是增加了一个接水工,也就是Selector,他负责协调,也就是看哪根水管有水了的话,在当前水管的水接到一定程度的时候,就切换一下:临时关上当前水龙头,试着打开另一个水龙头(看看有没有水)。
当其他人需要用水的时候,不是直接去接水,而是事前提了一个水桶给接水工,这个水桶就是Buffer。也就是,其他人虽然也可能要等,但不会在现场等,而是回家等,可以做其它事去,水接满了,接水工会通知他们。
这其实也是非常接近当前社会分工细化的现实,也是统分利用现有资源达到并发效果的一种很经济的手段,而不是动不动就来个并行处理,虽然那样是最简单的,但也是最浪费资源的方式。
网络编程
1.概述
邮件:
- 计算机网络: 计算机网络是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统。
- 网络编程的目的:无线电台…传播交流信息,数据交换,通信。
- 想要达到这个效果需要什么:
- 如何让准确的定位网络上的一台主机 192.168.16.124:端口, 定位上这个计算机上的某个资源。
- 找到了这个主机,如何传输数据呢?
- Javaweb:网页编程 、 B/S架构
- 网络编程:TCP/IP 、 C/S
2.网络通信要素
如何实现网络的通信?
- 通信双方的地址:
- ip:192.168.16.124
- 端口:5900
- 规则:网络通信的协议:TCP/IP
小结:
- 网络编程中有两个主要的问题:
- 如何让准确的定位到网络上的一台或多台主机;
- 找到主机之后如何通信;
- 网络编程中的要素:
- IP和端口号:IP
- 网络通信协议:UDP、TCP
- 万物皆对象
3.IP
IP 地址:InetAddress
唯一定位一台网络上的计算机
127.0.0.1: 本机localhost
ip地址的父类
- ==IPV4==: 127.0.0.1 ,4个字节组成。,0
255, 42亿;30亿都在北美,亚洲4亿。2011年就用尽; - ==IPV6==: fe80::f0e0:7383:ad8e:f32f%3 ,128位。8个无符号整数
1
2406:da18:ddf:4000:67d5:b226:cad7:125b
- ==IPV4==: 127.0.0.1 ,4个字节组成。,0
公网(互联网)–私网(局域网)
192.168.xx.xx,专门给组织内部使用。
域名:记忆IP问题!
- IP:www.vip.com
1 | import java.net.InetAddress; |
1 | /127.0.0.1 |
4.端口
端口表示计算机上一个程序的进程;
不同的进程有不同的端口号!用来区分软件!
被规定0~65535
TCP,UDP:65535*2个端口 tcp:80 udp:80 单个协议下,端口号不能冲突
端口分类
- 共有端口 0~1023 内置的进程使用
- HTTP:80
- HTTP:443 如访问https://www.baidu.com:443 访问的还是百度
- FTP:21
- TELENT:23
- 程序注册端口:1014-49151,分配给用户和程序
- Tomcat:8080
- MySql:3306
- Oracle:1521
- 动态、私有端口:49152~65535
- 共有端口 0~1023 内置的进程使用
1 | netstat -ano #查看所有的端口 |
5.通信协议
协议:约定,就好比中国人交流说的是普通话
网络通信协议: 速率,传输码率,代码结构,传输控制…
问题:非常的复杂
大事化小:分层
TCP/IP协议簇:实际上是一组协议
重要:
- TCP:用户传输协议
- UDP:用户数据报协议
出名的协议:
- TCP:
- IP:网络互联协议

CP UDP 对比**
TCP:打电话
连接,稳定
三次握手,四次挥手
1
2
3
4
5
6
7
8
9最少需要三次,保证稳定连接!
A:你瞅啥?
B:瞅你咋地?
A:干一场
A:我要分手了
B:我知道你要分手了
B:你真的要分手吗?
A:我真的要分手了客户端、服务器
传输完成,释放连接,效率低
UDP;发短信
- 不连接,不稳定
- 客户端、服务端:没有明确的解现
- 不管有没有准备好,都可以发给你
- DDOS:洪水攻击! 发垃圾包 堵塞线路 (饱和攻击)
6.TCP
先启动服务端,再启动客户端!!!!
客户端
- 连接服务器 Socket
- 发送消息
1 | import java.io.IOException; |
服务器端
- 建立服务的端口 ServerSocket
- 等待的用户的连接 accept
- 接收用户的消息
1 | import java.io.ByteArrayOutputStream; |
2.初识Tomcat
Tomcat乱码: conf\logging.properties 把UTF-8改为GBK
服务端
- 自定义 S
- Tomcat服务器 S :Java后台开发
客户端
- 自定义 C
- 浏览器 B
7.UDP
发短信:不用连接,需要知道对方的地址
1.发送消息
1 | import java.io.IOException; |
1 | import java.io.IOException; |

- 长串乱码是接受使用的1024的byte
8.URL
统一资源定位符:定位互联网上的某一个资源
DNS域名解析 www.baidu.com —> xxx.xxx.xxxx.xxx…xxx
1 | 协议://ip地址:端口号/项目名/资源 |
多线程
1、线程实现
1.线程的创建(三种方式)
1.1 继承Thread类(重要)
- 自定义线程类继承
Thread类;- 重写
run()方法,编写线程执行体;- 创建线程对象,调用
start()方法启动线程。
- 可以直接使用lambo表达式开启多线程
1 | for (int i = 0; i < 10; i++) { |
1.2 实现Runnable接口
- 推荐使用Runnable对象,因为Java单继承的局限性;
- 自定义线程类实现
Runnable接口;- 实现
run()方法,编写线程执行体;- 创建线程对象,调用
start()方法启动对象。
1.3 实现Callable接口(了解)
- 实现Callable接口,需要返回值类型;
- 重写call方法,需要抛出异常;
- 创建目标对象;
- 创建执行服务:ExecutorService ser = Executors.newFixedThreadPool(1);
- 提交执行:Future result1 = ser.submit(11);
- 获取结果:boolean r1 = result1.get();
- 关闭服务:ser.shutdownNow();
2.静态代理

- 总结
- 真实对象和代理对象都要实现一个接口;
- 代理对象要代理真实角色。
- 好处
- 代理对象可以做很多真实对象做不了的事情;
- 真实对象专注做自己的事。
3.Lambda表达式

- λ 希腊字母表中排序第十一位的字母,英语名称为 Lambda;
- 避免匿名内部类定义过多;
- 其实质属于函数式编程的概念;
- 去掉了一堆没有意义的代码,只留下核心逻辑。
(params)-> expression[表达式]
(params) -> statement[语句]
(params)-> {statements}
- new Thread (()->System.out.println(“多线程学习。。。。”)).start();
- 理解Functional Interface (函数式接口) 是学习Java 8 lambda表达式的关键
函数式接口的定义
- 任何接口,如果只包含唯一一个抽象方法,那么它就是一个函数式接口。
1 | public interface Runnable{ |
- 对于函数式接口,我们可以通过Lambda表达式来创建该接口的对象。
2、线程状态
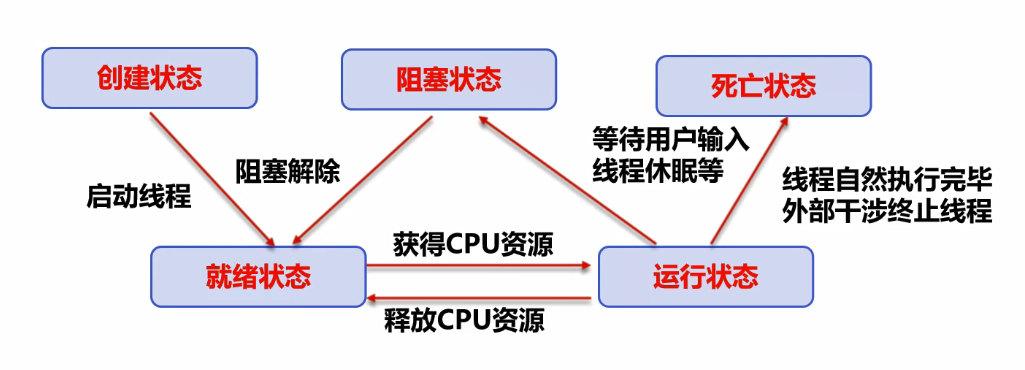
1 、线程的五大状态
2、线程方法
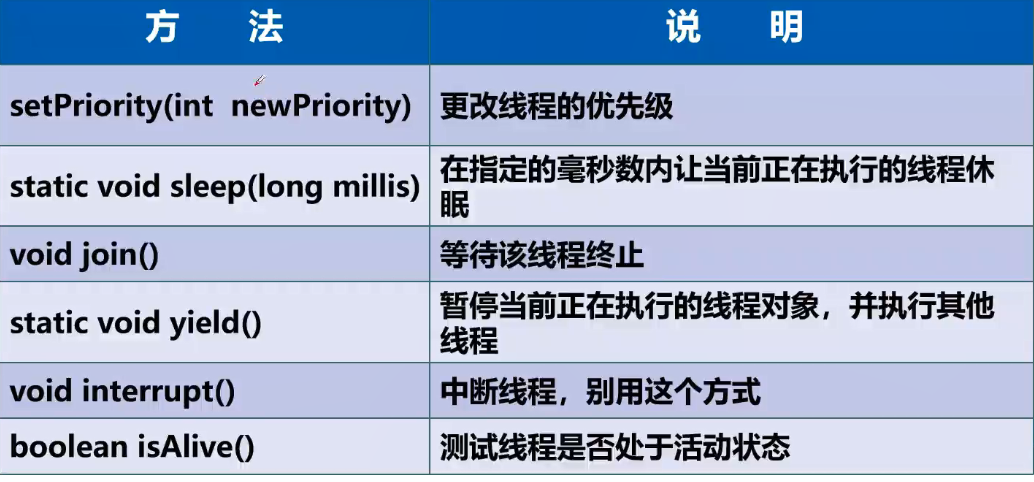
停止线程

线程休眠

线程礼让
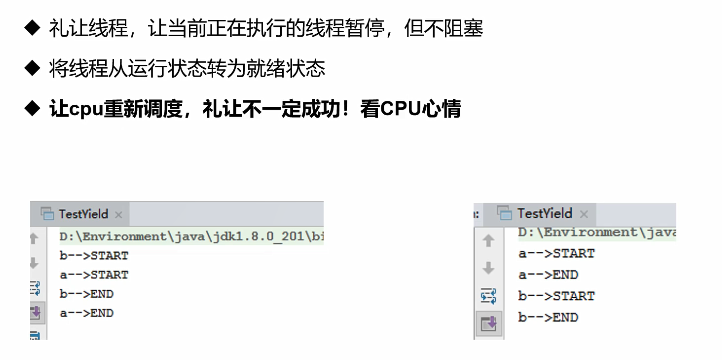
线程插队

3.线程状态观测

4、线程优先级

5、守护线程
- 线程分为用户线程和守护线程;
- 虚拟机必须确保用户线程执行完毕;
- 虚拟机不用等待守护线程执行完毕;
- 如,后台记录操作日志,监控内存垃圾回收等待……
3、线程同步
1.介绍
- **多个线程操作同一个资源 **
- 并发:同一个对象被多个线程同时操作

线程同步:
- 现实生活中我们会遇到“同—个资源,多个人都想使用”的问题,比如食堂排队打饭,每个人都想吃饭,最天然的解決办法就是:排队,一个个来。
- 处理多线程问题时,多个线程访问同一个对象,并且某些线程还想修改这个对象这时候我们就需要线程同步。线程同步其实就是一种等待机制,多个需要同时访问此对象的线程进入这个==对象的等待池形==成队列,等待前面线程使用完毕,下一个线程再使用。
- 队列和锁
线程同步:
- 由于同一进程的多个线程共享同一块存储空间,在带来方便的同时,也带来了访问冲突问题,为了保证数据在方法中被访问时的正确性,在访问时加入锁机制synchronized,当一个线程获得对象的排它锁,独占资源,其他线程必须等待使用后释放锁即可。存在以下问题:
- 一个线程持有锁会导致其他所有需要此锁的线程挂起;
- 在多线程竞争下,加锁,释放锁会导致比较多的上下文切换和调度延时,引起性能问题;
- 如果一个优先级高的线程等待个优先级低的线程释放锁会导致优先级倒置,引起性能问题。
2、同步方法
- 由于我们可以通过 private关键字来保证数据对象只能被方法访问,所以我们只需要针对方法提岀一套机制,这套机制就是syη chronized关键字,它包括两种用法synchronized方法和 synchronized块。
- 同步方法:public synchronized void method (int args) {}
- synchronized方法控制对“对象”的访问,每个对象对应一把锁,每个synchronized方法都必须获得调用该方法的对象的锁才能执行,否则线程会阻塞,方法一旦执行,就独占该锁,直到该方法返回才释放锁,后面被阻塞的线程才能获得这个锁,继续执行。
- 缺陷:若将一个大的方法申明为 synchronized将会影响效率。
1 | public class SynDemo { |
加锁前:
加锁后:
3.同步块
- 同步块:synchronized (Obj) {}
- obj称之为同步监视器
- Obj可以是任何对象,但是推存使用共享资源作为同步监视器。
- 同步方法中无需指定同步监视器,因为同步方法的同步监视器就是this,就是这个对象本身,或者是class。
- 同步监视器的执行过程:
- 1.第一个线程访问,锁定同步监视器,执行其中代码;
- 2.第二个线程访问,发现同步监视器被锁定,无法访问;
- 3.第一个线程访问完毕,解锁同步监视器;
- 4.第二个线程访问,发现同步监视器没有锁,然后锁定并访问。
锁的对象就是变量的量,需要增删改查的对象
1 | public class SynDemo2 { |
4.死锁
- 多个线程各自占有一些共享资源,并且互相等待其他线程占有的资源才能运行,而导致两个或者多个线程都在等待对方释放资源,都停止执行的情形。某一个同步块同时拥有“两个以上对象的锁”时,就可能会发生“死锁”的问题。
死锁:多个线程互相抱着对方需要的资源,然后形成僵持
解决:一个锁只锁一个对象
1 | public class DeadLockDemo { |
避免死锁的办法
- 产生死锁的四个必要条件
- 1.互斥条件:一个资源毎次只能被一个进程使用。
- 2.请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 3.不剥夺条件∶进程已获得的资源,在末使用完之前,不能强行剥夺。
- 4.循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
- 上面列出了死锁的四个必要条件,我们只要想办法破其中的任意一个或多个条件就可以避免死锁发生。
5、Lock(锁)
- 从JDK 5.0开始, Java提供了更强大的线程同步机制一通过显式定义同步锁对象来实现同步。同步锁使用Lock对象充当。
- java.util.concurrent.locks.Lock接口是控制多个线程对共享资源进行访问的工具。锁提供了对共享资源的独占访问,每次只能有一个线程对Lock对象加锁,线程开始访问共享资源之前应先获得Lock对象。
- ReentrantLock 类实现了 Lock,它拥有与 synchronized 相同的并发性和内存语义,在实现线程安全的控制中,比较常用的是ReentrantLock, 可以显式加锁、释放锁。
1 | class A{ |
6.synchroized与Lock对比
- Lock是显式锁 (手动开启和关闭锁,别忘记关闭锁) synchronized是隐式锁, 出了作用域自动释放。
- Lock只有代码块锁, synchronized有代码块锁和方法锁。
- 使用Lock锁,JVM将花费较少的时间来调度线程, 性能更好。并且具有更好的扩展性 (提供更多的子类)。
- 优先使用顺序:
- Lock > 同步代码块 (已经进入了方法体,分配了相应资源 $)>$ 同步方法 (在方法体之外)
4.线程通信问题
- 应用场景 : 生产者和消费者问题
- 假设仓库中只能存放一件产品 , 生产者将生产出来的产品放入仓库,消费者将仓库中产品取走消费。
- 如果仓库中没有产品 , 则生产者将产品放入仓库,否则停止生产并等待,直到仓库中的产品被消费者取走为止。
- 如果仓库中放有产品 , 则消费者可以将产品取走消费,否则停止消费并等待,直到仓库中再次放入产品为止。
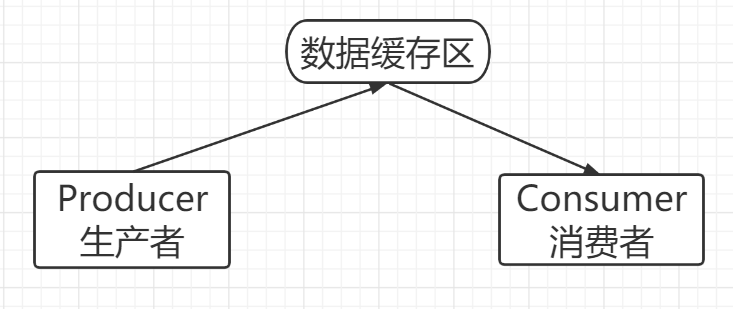
1.线程通信方法
- Java提供了几个方法解决线程之间的通信问题。
| 方法名 | 作用 |
|---|---|
| wait() | 表示线程一直等待,直到其他线程通知,与sleep不同会释放锁。 |
| wait(long timeout) | 指定等待的毫秒数。 |
| notify() | 唤醒一个处于等待状态的线程。 |
| notifyAll() | 唤醒同一个对象上所有调用wait()方法的线程,优先级别高的线程优先调度。 |
- 注意:均是 Object类的方法,都只能在同步方法或者同步代码块中使用,否则会抛出异常IIIegalMonitorStateException。
- 这是一个线程同步问题,生产者和消费者共享同一个资源,并且生产者和消费者之间相互依赖,互为条件:
- 对于生产者,没有生产产品之前,要通知消费者等待。而生产了产品之后,又需要马上通知消费者消费。
- 对于消费者,在消费之后,要通知生产者已经结束消费,需要生产新的产品以供消费。
- 在生产者消费者问题中,仅有 synchronized是不够的:
- synchronized可阻止并发更新同一个共享资源,实现了同步;
- synchronized不能用来实现不同线程之间的消息传递通信。
2.线程通信问题解决方式
解决方式一:
- 并发协作模型“生产者/消费者模式”–>管程法:
- 生产者∶负责生产数据的模块(可能是方法,对象,线程,进程);
- 消费者:负责处理数据的模块(可能是方法,对象,线程,进程);
- 缓冲区:消费者不能直接使用生产者的数据,他们之间有个“缓冲区”。
- 生产者将生产好的数据放入缓冲区,消费者从缓冲区拿出数据。
5.线程池
- 背景:经常创建和销毁、使用量特别大的资源,比如并发情况下的线程,对性能影响很大。
- 思路:提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁、实现重复利用。类似生活中的公共交通工具。
- 好处:
- 提高响应速度(减少了创建新线程的时间);
- 降低资源消耗(重复利用线程池中线程,不需要毎次都创建);
- 便于线程管理(…)
- corePoolsize:核心池的大小;
- maximumPoolSize:最大线程数;
- keepAliveTime:线程没有任务时最多保持多长时间后会终止。
- JDK 5.0起提供了线程池相关AP:ExecutorService和 Executors。
- ExecutorService:真正的线程池接口。常见子类 ThreadPoolExecutor。
- void execute( Runnable command):执行任务命令,没有返回值,一般用来执行 Runnable;
Future submit( Callable 妇ask):执行任务,有返回值,一般又来执行Callable; - void shutdown():关闭连接池。
- Executors:工具类、线程池的工厂类,用于创建并返回不同类型的线程池。
多线程还得看JUC,后边也还会再记录的
注解与反射
注解使用的更多的是在后边的spring、springboot的框架中,会大量使用到各种注解。
1、注解
1、注解入门
Annotation是jdk1.5开始引入的新技术。
Annotation的作用:
- 不是程序本身,可以对程序作出解释;
- 可以被其他程序(例如编译器)读取。
Annotation的格式
- “@注解名”,也可以带参数,例如:@SuppressWarnings(value=“unchcked”)
Annotation在哪里使用?
- 可以附加在package、class、method、field上,相当于给它们添加了额外的辅助信息,还可以通过反射机制编程实现对这些元数据的访问。
2.内置注解
- @ Override:定义在 java. lang Override中,此注释只适用于修辞方法,表示一个方法声明打算重写超类中的另一个方法声明。
- @ Deprecated:定义在 Java. lang. Deprecated中,此注释可以用于修辞方法,属性,类,表示不鼓励程序员使用这样的元素,通常是因为它很危险或者存在更好的选择。
- @ SuppressWarnings:定义在 Java. lang. SuppressWarnings中,用来抑制编译时的警告信息。
- 与前两个注释有所不同,你需要添加一个参数才能正确使用,这些参数都是已经定义好了的,我们选择性的使用就好了。
- @SuppressWarnings ( “all”)
- @SuppressWarnings (unchecked”)
- @ SuppressWarnings(value=f”unchecked”, “ deprecation “)
- 等等……
3、自定义注解
- 元注解的作用就是负责注解其他注解,Java定叉了4个标准的meta- annotation类型,他们被用来提供对其他 annotation类型作说明。
- 这些类型和它们所支持的类在 java. lang annotation包中可以找到。(@Target,@Retention,@Documented, @Inherited)
- @ Target:用于描述注解的使用范围(即被描述的注解可以用在什么地方)。
- @ Retention:表示需要在什么级别保存该注释信息,用于描述注解的生命周期。
- SOURCE < CLASS < RUNTIME
- @ Document:说明该注解将被包含在 Javadoc中。
- @ Inherited:说明子类可以继承父类中的该注解。
自定义注解
- 使用@ interface自定义注解时,自动继承了 java. lang annotation. Annotation接口。
- 分析:
- @ interface用来声明一个注解,格式:public@ interface注解名{定义内容}
- 其中的每一个方法实际上是声明了一个配置参数;
- 方法的名称就是参数的名称。
- 返回值类型就是参数的类型(返回值只能是基本类型, Class, String,enum)
- 可以通过 defau来声明参数的默认值;
- 如果只有一个参数成员,一般参数名为vaue;
- 注解元素必须要有值,我们定义注解元素时,经常使用空字符串,0作为默认值
2、反射机制
1.Java反射机制概念
- 静态 & 动态语言
- 动态语言
- 是一类在运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。通俗点说就是在运行时代码可以根据某些条件改变自身结构。
- 主要动态语言:Object-C、C#、 JavaScript、PHP、 Python等。
- 静态语言
- 与动态语言相对应的,运行时结构不可变的语言就是静态语言。如Java、C、C++。
- Java不是动态语言,但Java可以称之为“准动态语言”。即Java有一定的动态性我们可以利用反射机制获得类似动态语言的特性。Java的动态性让编程的时候更加灵活。
- 反射机制概念
- Reflection(反射)是Java被视为动态语言的关键,反射机制允许程序在执行期借助于 Reflection AP取得仼何类的内部信息,并能直接操作任意对象的内部属性及方法。
- Class c= Class.forName(“java. lang String”);
- 加载完类之后,在堆內存的方法区中就产生了一个 Class类型的对象(一个类只有一个Cass对象),这个对象就包含了完整的类的结构信息。我们可以通过这个对象看到类的结构。这个对象就像一面镜子,透过这个镜子看到类的结构,所以,我们形象的称之为:反射。

- 反射机制研究与应用
- Java反射机制提供的功能
- 在运行时判断任意一个对象所属的类;
- 在运行时构造任意一个类的对象;
- 在运行时判断任意一个类所具有的成员变量和方法;
- 在运行时获取泛型信息;
- 在运行时调用任意一个对象的成员变量和方法;
- 在运行时处理注解;
- 生成动态代理;
- ……
- 反射机制优缺点
- 优点:
- 可以实现动态创建对象和编译,体现出很大的灵活性。
- 缺点
- 对性能有影响。使用反射基本上是一种解释操作,我们可以告诉JVM,我们希望做什么并且它满足我们的要求。这类操作总是慢于直接执行相同的操作。
/*
一个类在内存中只有一个Class对象
一个类被加载后,类的整个结构都会被封装在Class对象中
public native int hashCode();返回该对象的hash码值
注:哈希值是根据哈希算法算出来的一个值,这个值跟地址值有关,但不是实际地址值。
*/
2.理解Class类并获取Class实例
- class类介绍
- 在 Object类中定义了以下的方法,此方法将被所有子类继承
- public final Class getclass()
- 以上的方法返回值的类型是一个 Class类,此类是Java反射的源头,实际上所谓反射从程序的运行结果来看也很好理解,即:可以通过对象反射求出类的名称。
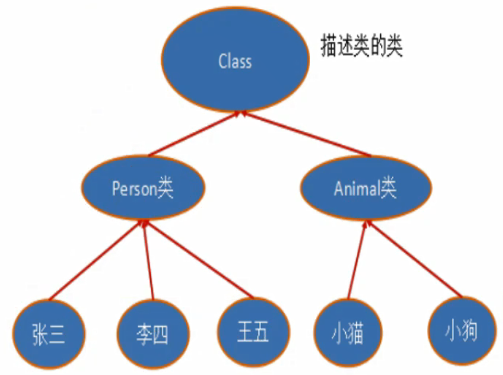
对象照镜子后可以得到的信息:某个类的属性、方法和构造器、某个类到底实现了哪些接口对于每个类而言,JRE都为其保留一个不变的Cass类型的对象。一个Class对象包含了特定某个结构( class/interface/enum/annotation/ primitive type/void/[])的有关信息。
- Class本身也是一个类;
- Class对象只能由系统建立对象;
- 一个加载的类在JVM中只会有一个Class实例;
- 一个Cass对象对应的是一个加载到JM中的一个class文件;
- 每个类的实例都会记得自己是由哪个Class实例所生成;
- 通过class可以完整地得到一个类中的所有被加载的结构;
- class类是 Reflection的根源,针对任何你想动态加载、运行的类,唯有先获得相应的Class对象。
class类的常用方法
| 方法名 | 功能说明 |
|---|---|
| static ClassforName (String name) | 返回指定类名name的class对象 |
| Object newInstance () | 调用缺省构造函数,返回 Class对象的一个实例 |
| getName () | 返回此Class对象所表示的实体(类,接口,数组类或void)的名称。 |
| Class getSuperClass () | 返回当前class对象的父类的class对象 |
| Class[] getinterfaces () | 获取当前 Class对象的接口 |
| ClassLoader getclassLoader () | 返回该类的类加载器 |
| Constructor getConstructors () | 返回一个包含某些 Constructor对象的数组 |
| Method getMothed (String name, Class…T) | 返回一个 Method对象,此对象的形参类型为paramType |
| Field[] getDeclaredFields () | 返回Field对象的一个数组 |
- 获取Class类的实例
- 若已知具体的类,通过类的class属性获取,该方法最为安全可靠,程序性能最高。
- Class clazz=Person.class;
- 已知某个类的实例,调用该实例的 getclass () 方法获取Class对象。
- Class clazz= person. getClass();
- 已知一个类的全类名,且该类在类路径下,可通过class类的静态方法 forName(获取,可能抛出 ClassNotFound Exception。
- Class clazz Class forName(”demo01 Student”);
- 内置基本数据类型可以直接用类名.Type。
- 还可以利用 Classloader。
- 哪些类型可以有Class对象
- class:外部类,成员(成员内部类,静态内部类),局部内部类,匿名内部类。
- interface:接口
- []:数组
- enum:枚举
- annotation:注解@interface
- primitive type:基本数据类型
- void
3.类的加载与ClassLoader
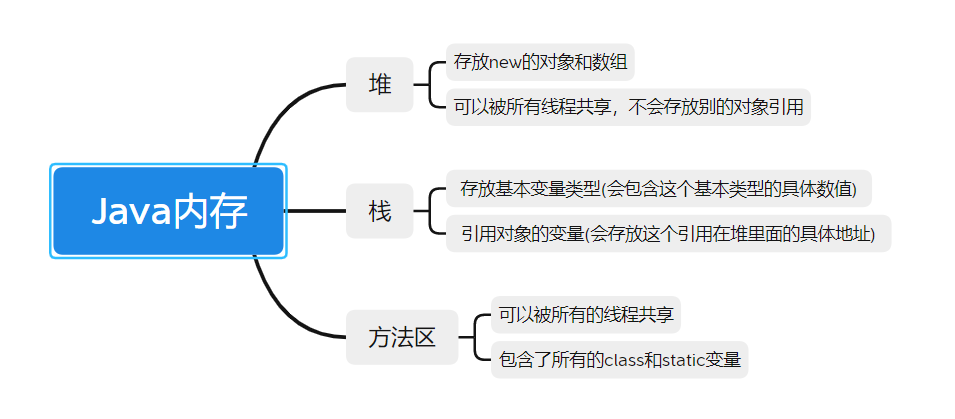
- Java内存分析
- 类的加载
- 当程序主动使用某个类时,如果该类还未被加载到内存中,则系统会通过如下三个步骤来对该类进行初始化。
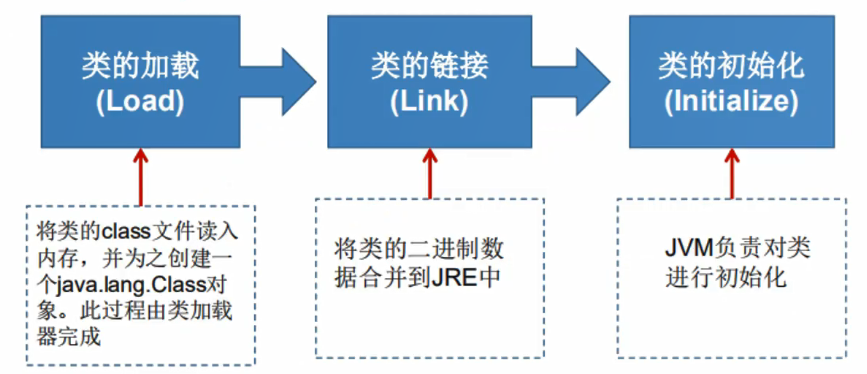
- 加载:将 class文件字节码內容加载到内存中,并将这些静态数据转换成方法区的运行时数据结构,然后生成一个代表这个类的 java. lang . Class对象。
- 链接:将Java类的二进制代码合并到JVM的运行状态之中的过程。
- 验证:确保加载的类信息符合JVM规范,没有安全方面的问题。
- 准备:正式为类变量( static)分配内存并设置类变量默认初始值的阶段,这些内存都将在方法区中进行分配。
- 解析:虚拟机常量池内的符号引用(常量名)替换为直接引用(地址)的过程。
- 初始化:
- 执行类构造器< clinit>方法的过程。类构造器< clinit>方法是由编译期自动收集类中所有类变量的赋值动作和静态代码块中的语句合并产生的。(类构造器是构造类信息的,不是构造该类对象的构造器)。
- 当初始化一个类的时候,如果发现其父类还没有进行初始化,则需要先触发其父类的初始化。
- 虛拟机会保证一个类的< clinit >()方法在多线程环境中被正确加锁和同步。
- 深刻理解类加载
- 什么时候会发生类初始化
- 类的主动引用(一定会发生类的初始化)
- 当虚拟机启动,先初始化main方法所在的类;
- new一个类的对象;
- 调用类的静态成员(除了fina常量)和静态方法;
- 使用 java. lang. reflect包的方法对类进行反射调用;
- 当初始化一个类,如果其父类没有被初始化,则先会初始化它的父类。
- 类的被动引用(不会发生类的初始化)
- 当访问一个静态域时,只有真正声明这个域的类才会被初始化。如:当通过子类引用父类的静态变量,不会导致子类初始化;
- 通过数组定义类引用,不会触发此类的初始化;
- 引用常量不会触发此类的初始化(常量在链接阶段就存入调用类的常量池中了)。
- 类加载器的作用
- 类加载的作用:将 class文件字节码内容加载到内存中,并将这些静态数据转换成方法区的运行时数据结构,然后在堆中生成一个代表这个类的 java. lang Class对象,作为方法区中类数据的访问入口。
- 类缓存:标准的 JavaSE类加载器可以按要求查找类,但一旦某个类被加载到类加载器中,它将维持加载(缓存)一段时间。不过JVM垃圾回收机制可以回收这些 Class对象
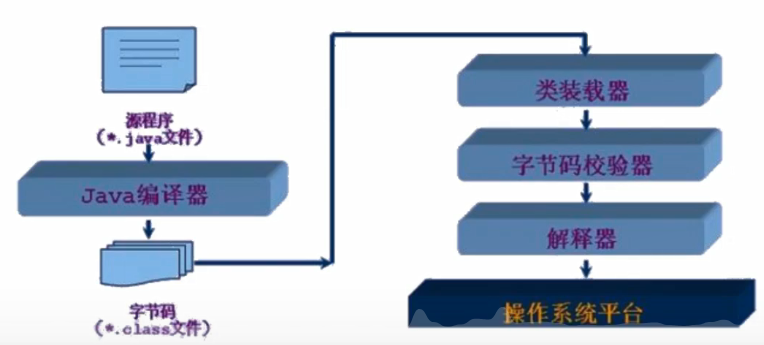
- 类加载器作用是用来把类(αlass)装载进内存的。JVM规范定义了如下类型的类的加载器。
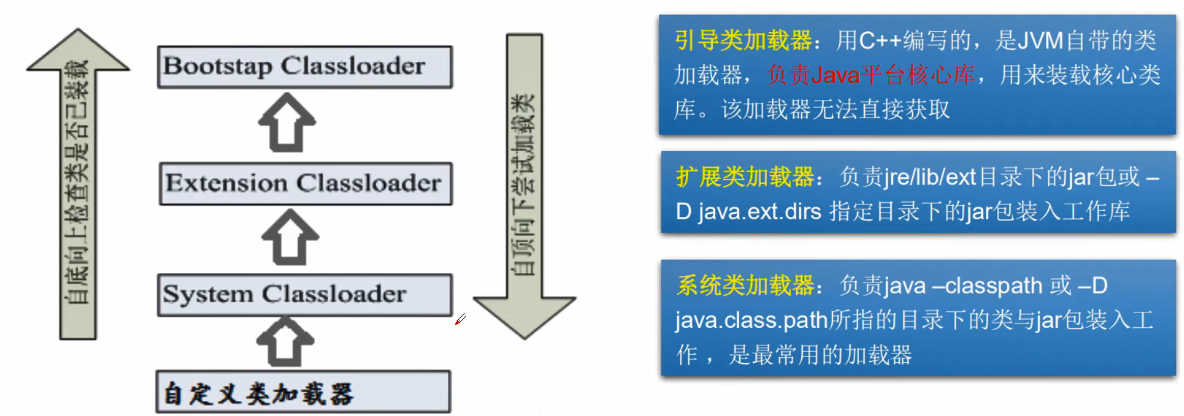
- ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader();//获取系统类的加载器
- ClassLoader parent = systemClassLoader.getParent();//获取系统类加载器的父类加载器–>扩展类加载器 jre1.8.0_91\lib\ext
- ClassLoader parent1 = parent.getParent();//获取扩展类加载器父类加载器–>根加载器(c/c++) jre1.8.0_91\lib\rt.jar
1 | public class ClassDemo1 { |
4.获取运行类的完整结构
通过反射获取运行时类的完整结构
Field、 Method、 Constructor.、 Superclass、 Interface、 Annotation
实现的全部接口
所继承的父类
全部的构造器
全部的方法
全部的Feld
注解
……
在实际的操作中,取得类的信息的操作代码,并不会经常开发。
一定要熟悉 java. lang .reflect包的作用,反射机制。
如何取得属性、方法、构造器的名称,修饰符等。
5.调用运行时类的指定结构
- 有Class对象,能做什么
- 创建类的对象:调用 Class对象的 newInstance()方法
- 1)类必须有一个无参数的构造器。
- 2)类的构造器的访问权限需要足够。
- 思考?难道没有无参的构造器就不能创建对象了吗?只要在操作的时候明确的调用类中的构造器,并将参数传递进去之后,才可以实例化操作。
- 步骤如下:
- 1)通过class类的 getDeclaredConstructor( Class…, parameterTypes)取得本类的指定形参类型的构造器;
- 2)向构造器的形参中传递一个对象数组进去,里面包含了构造器中所需的各个参数。
- 3)通过 Constructo实例化对象
2、方法及使用
通过反射,调用类中的方法,通过 Method类完成。
- ①通过Cas类的 getMethod( String name, Class… parameterTypes)方法取得一个 Method对象,并设置此方法操作时所需要的参数类型。
- ②之后使用 Object invoke( Object obj,Object[] args)进行调用,并向方法中传递要设置的ob对象的参数信息。
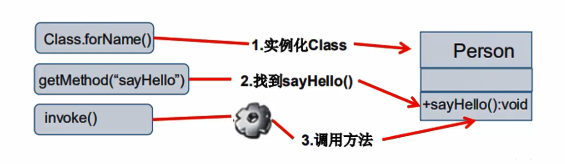
调用指定的方法:
- Object invoke(object obj, Object. args)
- Object对应原方法的返回值,若原方法无返回值,此时返回null;
- 若原方法若为静态方法,此时形参 Object obj可为null;
- 若原方法形参列表为空,则 Object[] args为null;
- 若原方法声明为 private,则需要在调用此 invoke()方法前,显式调用方法对象的setAccessible(true)方法,将可访问 private的方法。
setAccessible
- Method和 Field、 Constructor对象都有 setAccessible()方法。
- setAccessible作用是启动和禁用访问安全检查的开关。
- 参数值为true则指示反射的对象在使用时应该取消Java语言访问检査。
- 提高反射的效率。如果代码中必须用反射,而该句代码需要频繁的被调用,那么请设置为true;
- 使得原本无法访问的私有成员也可以访问;
- 参数值为false则指示反射的对象应该实施Java语言访问检查。
- 性能检测
1 | 经过反复测试得出结论:普通方式执行效率 > 反射关闭检测方式执行效率 > 反射方式执行效率 |
6.反射操作泛型
- Java采用泛型擦除的机制来引入泛型,Java中的泛型仅仅是给编译器javac使用的,确保数据的安全性和免去强制类型转换问题,但是,一旦编译完成,所有和泛型有关的类型全部擦除。
1 | 泛型: |
1 | 那么泛型是什么??? |
7.反射操作注解
- getAnnotations
- getAnntation
JAVA SE总结
